У цьому посібнику ми дослідимо світ веб-скрепінгу - потужного методу вилучення даних з веб-сайтів.
Незалежно від того, чи ви новачок, якому цікава ця концепція, чи досвідчений програміст, який прагне вдосконалити свої навички, у цьому посібнику знайдеться щось цінне для кожного. У ньому ви знайдете все: від розуміння основ вилучення даних HTML за допомогою селекторів CSS та XPath до практичного вилучення даних з веб-сторінок за допомогою Python. Крім того, ми розглянемо юридичні аспекти, етичні міркування та найкращі практики для забезпечення відповідального веб-скрепінгу.

Застереження. Цей матеріал був розроблений виключно в інформаційних цілях. Він не є схваленням будь-якої діяльності (в тому числі незаконної), продуктів або послуг. Ви несете повну відповідальність за дотримання чинного законодавства, включаючи закони про інтелектуальну власність, під час використання наших послуг або покладаючись на будь-яку інформацію, що міститься тут. Ми не несемо жодної відповідальності за шкоду, що виникла внаслідок використання наших послуг або інформації, що міститься тут, у будь-який спосіб, за винятком випадків, коли це прямо передбачено законодавством.
Зміст.
- Що таке веб-скрепінг і як він працює?
- Основи вилучення даних з HTML: Селектори CSS та XPath.
- Веб-скрепінг за допомогою Python (+ код).
- Чи законний веб-скрепінг?
- Як веб-сайти намагаються заблокувати веб-скрепінг?
- Етичні та найкращі практики веб-скрепінгу.
- Веб-скрепінг: Поширені запитання (FAQ)
- Висновок.
1. Що таке веб-скрепінг і як він працює?
Веб-скрепінг (також відомий як веб-збирання або вилучення даних) - це процес автоматичного вилучення даних з веб-сайтів, веб-сервісів і веб-додатків.
Веб-скрепінг допомагає позбавити нас від необхідності заходити на кожен веб-сайт і вручну витягувати дані - довгого і неефективного процесу. Процес передбачає використання автоматизованих скриптів або програм. Скрипт або програма отримує доступ до HTML-структури веб-сторінки, аналізує дані і витягує конкретні необхідні елементи сторінки для подальшого аналізу.
a. Для чого використовується веб-скрепінг?
Веб-скрепінг - це фантастична річ, якщо підходити до нього відповідально. Як правило, його можна використовувати для дослідження ринків, наприклад, для отримання інформації та вивчення тенденцій на конкретному ринку. Він також популярний у моніторингу конкурентів, щоб відстежувати їхню стратегію, ціни тощо.
Більш конкретні випадки використання:
- Соціальні платформи (Скрейпінг Facebook і Twitter)
- Онлайн-моніторинг зміни цін,
- Відгуки про товари,
- SEO-кампанії,
- Оголошення про нерухомість,
- Відстеження погодних даних,
- Відстеження репутації сайту,
- Моніторинг доступності та цін на авіаквитки,
- Тестуйте рекламу, незалежно від географії,
- Моніторинг фінансових ресурсів,
b. Як працює веб-скрепінг?
Типовими елементами, що беруть участь у веб-скрепінгу, є ініціатор і ціль. Ініціатор (веб-скрепер) використовує програмне забезпечення для автоматичного вилучення даних з веб-сайтів. З іншого боку, мішенню зазвичай є вміст веб-сайту, контактна інформація, форми або будь-що загальнодоступне в Інтернеті.
Типовий процес виглядає наступним чином:
- КРОК 1: Ініціатор використовує інструмент скрепінгу - програмне забезпечення (це може бути як хмарний сервіс, так і саморобний скрипт), щоб почати генерувати HTTP-запити (використовуються для взаємодії з веб-сайтами та отримання даних). Це програмне забезпечення може ініціювати будь-який HTTP-запит - від GET, POST, PUT, DELETE або HEAD до OPTIONS-запиту до цільового веб-сайту.
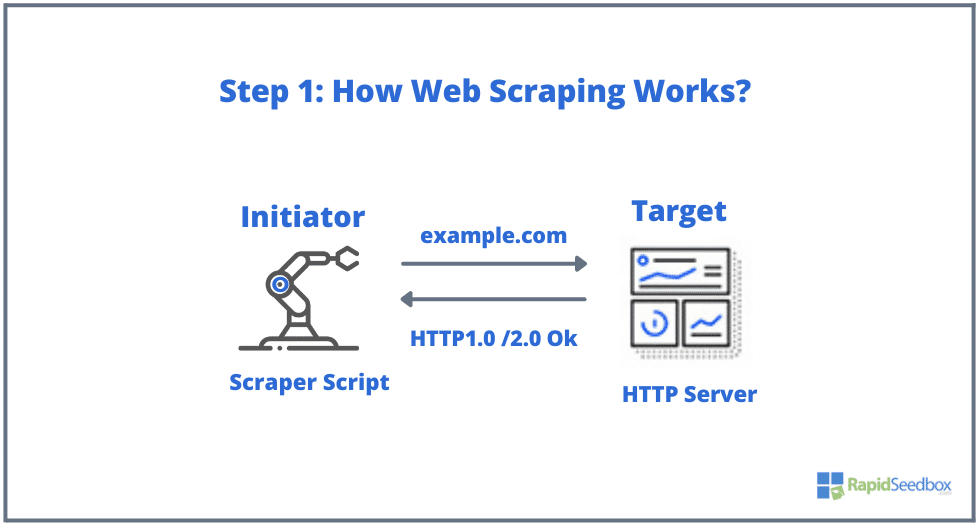
- КРОК 2. Якщо сторінка існує, цільовий веб-сайт відповість на запит скрепера HTTP/1.0 200 OK (типова відповідь відвідувачам). Коли скрепер отримає HTML-відповідь (наприклад, 200 OK), він почне аналізувати документ і збирати його неструктуровані дані.
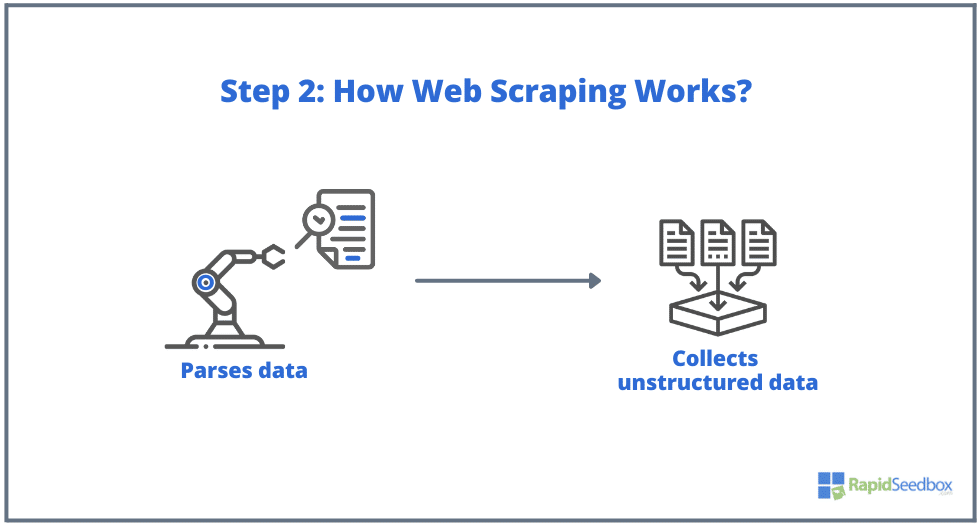
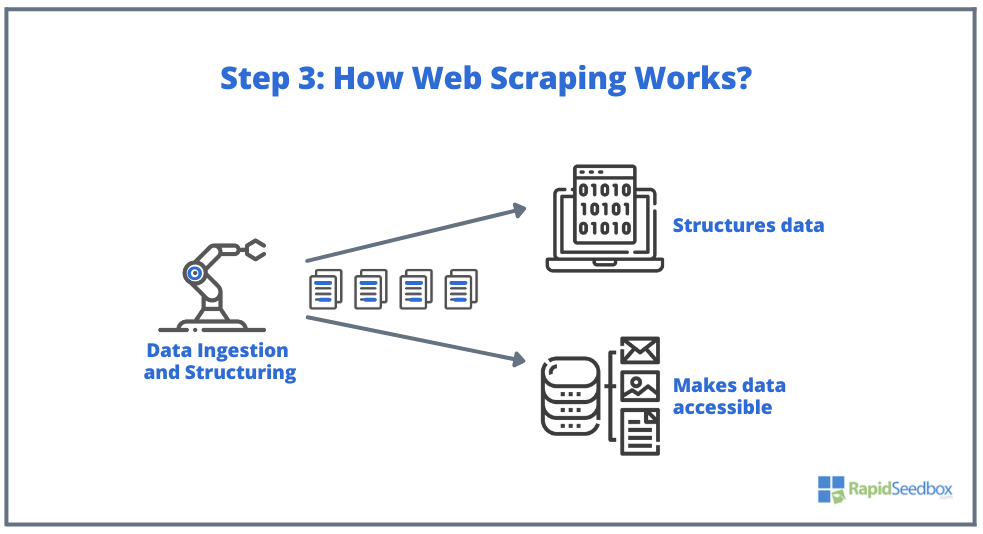
- КРОК 3. Потім програма-скрепер витягує необроблені дані, зберігає їх і додає структуру (індекси) до даних відповідно до того, що було вказано ініціатором. Структуровані дані доступні у читабельних форматах, таких як XLS, CSV, SQL або XML.
2. Основи вилучення даних з HTML: Селектори CSS та XPath.
Можливо, ви вже знаєте основи: Веб-скрепінг передбачає вилучення даних з веб-сайтів, і все починається з HTMLоснова веб-сторінок. У HTML-файлі ви знайдете класи та ідентифікатори, таблиці, списки, блоки або контейнери - всі основні елементи, з яких складається структура сторінки.
З іншого боку, CSS - це мова таблиць стилів, яка використовується для керування презентацією та макетом HTML-документів. Вона визначає, як елементи HTML відображаються на веб-сторінці, наприклад, кольори, шрифти, відступи та позиціонування. CSS відіграє ключову роль у веб-скрепінгу, оскільки допомагає витягувати дані з потрібних елементів.
Примітка. Докладне пояснення того, що таке HTML і CSS та як вони працюють, виходить за рамки цієї статті. Ми припускаємо, що ви вже володієте базовими навичками роботи з HTML і CSS.
Хоча можна було б витягти дані безпосередньо з необробленого HTML за допомогою різних методів, наприклад, регулярних виразів, це може зайняти багато часу і бути складним завданням. Оскільки структурована мова HTML була розроблена, щоб бути "машинозчитуваною", вона може бути дуже складною і різноманітною. Саме тут селектори CSS та XPath відіграють ключову роль.
a. Компіляція та перевірка HTML.
У наступному розділі ми надамо кілька прикладів CSS і селекторів XPath (скомпільованих і перевірених). Усі наведені нижче приклади HTML і CSS було скомпільовано за допомогою онлайн-редактора HTML-CSS-JS.
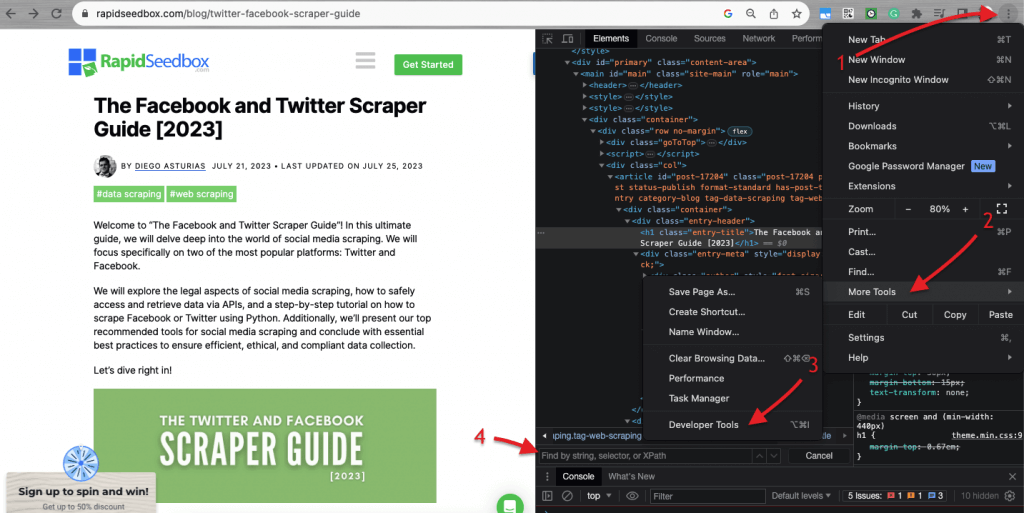
Коли мова йде про перевірку HTML-коду на веб-сайтах, Веб-браузери постачаються з Інструментами розробника, тому ви можете буквально перевіряти HTML або CSS, які є загальнодоступними на будь-якому веб-сайті. Ви можете клацнути правою кнопкою миші на веб-сторінці і вибрати "Перевірити", "Перевірити елемент" або "Перевірити джерело". Для кращого динамічного порівняння сторінок і коду в браузері Chrome > перейдіть до трьох крапок у верхньому лівому куті (1) > Більше інструментів (2) > Інструменти розробника (3).
Інструменти розробника мають зручний фільтр пошуку (4), який дозволяє шукати за рядком, селектором або XPath. Для прикладу, ми витягнемо деякі дані з: https://www.seedhost.net/wp/blog/twitter-facebook-scraper-guide.
b. Селектори CSS:
Селектори CSS - це шаблони, які використовуються для вибору та націлювання HTML-елементів веб-сторінки. Вони корисні для веб-скрепінгу (і стилізації), оскільки забезпечують більш ефективний і цілеспрямований спосіб отримання даних з HTML-документів. Хоча можна отримати дані безпосередньо з вихідного HTML за допомогою різних методів, наприклад, регулярних виразів, CSS-селектори мають кілька переваг, які роблять їх кращим вибором для веб-скрепінгу.
Методи націлювання та виділення HTML-елементів на веб-сторінці:
i. Вибір вузла.
Виділення вузлів - це процес вибору елементів HTML на основі імен їхніх вузлів. Наприклад, вибір всіх елементів 'p' або всіх елементів 'a' на сторінці. Ця техніка дозволяє вам сфокусуватися на певних типах елементів в HTML-документі.

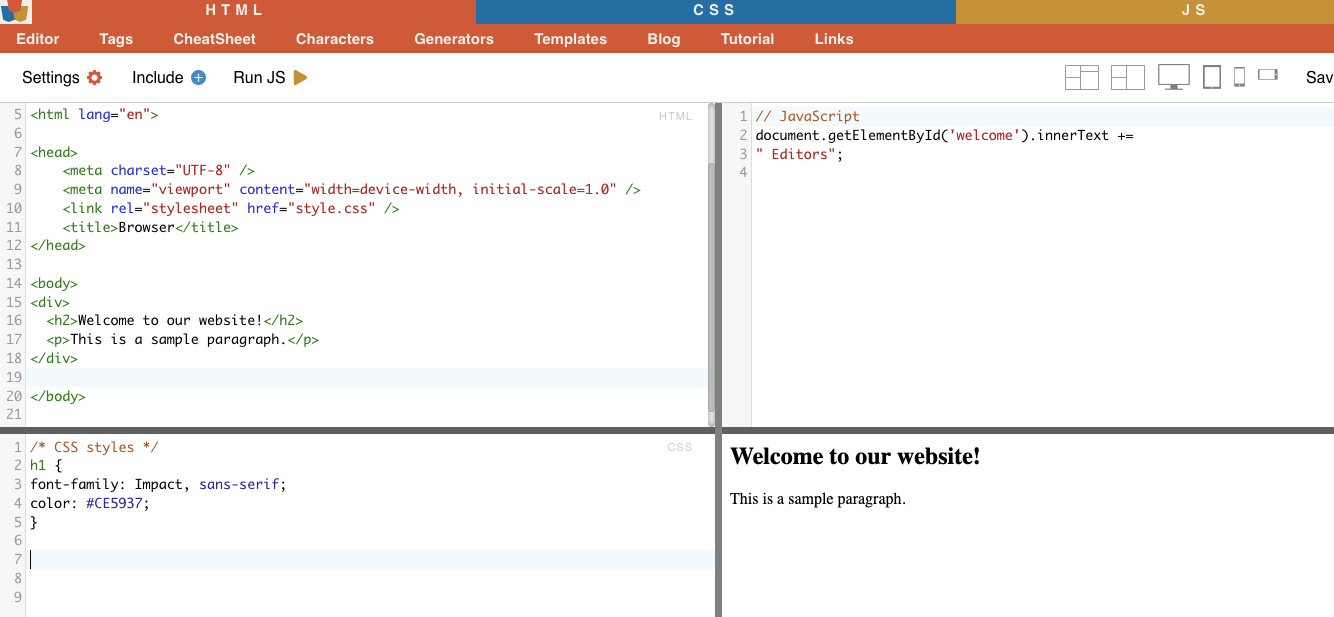
Приклад з реального життя: Ручний пошук H2s.
Другий. Клас.
У селекторах CSS вибір класу передбачає вибір HTML-елементів на основі присвоєного їм атрибута класу. Атрибут class дозволяє застосувати певну назву класу до одного або декількох елементів. Крім того, в стилях CSS або JavaScript його можна застосувати до всіх елементів з цим класом. Прикладами назв класів є кнопки, елементи форм, меню навігації, макети сітки тощо.
Приклад: Наступний CSS-селектор: 'highlight' виділить усі елементи з атрибутом class, що має значення 'highlight'.


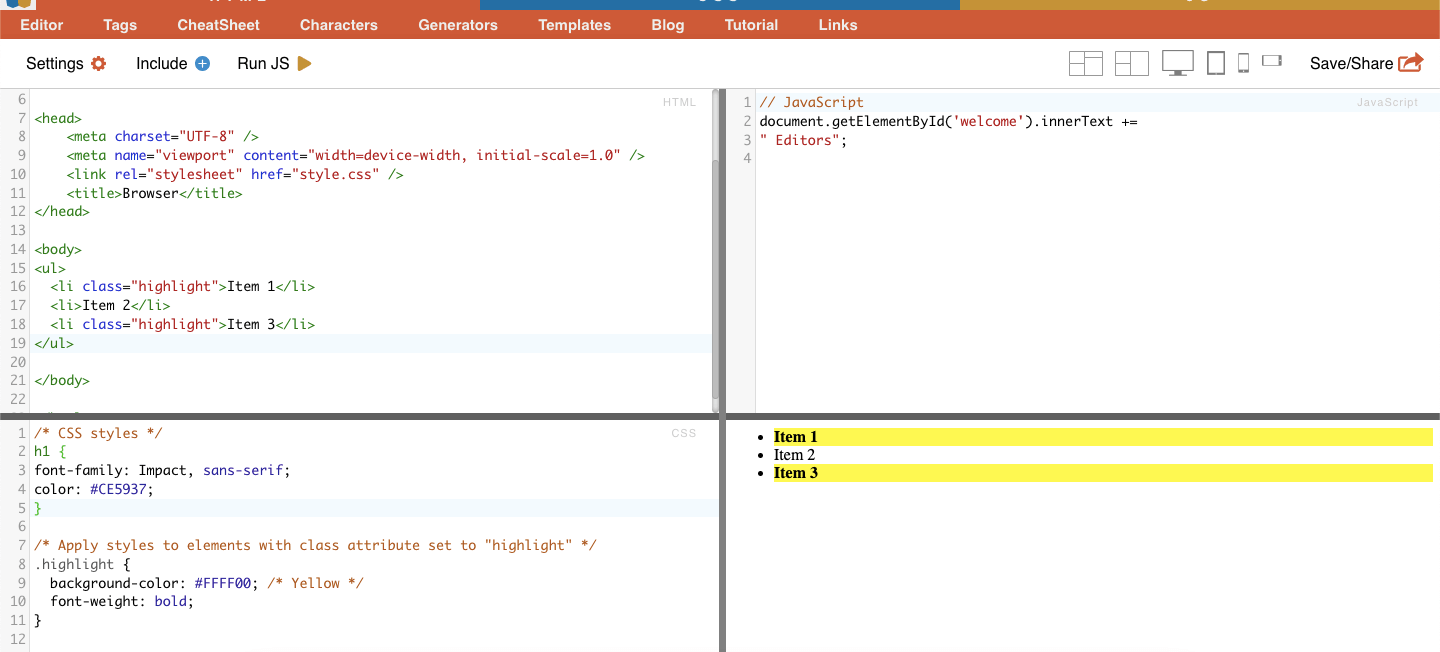
Приклад з реального життя: Ручний пошук класів.
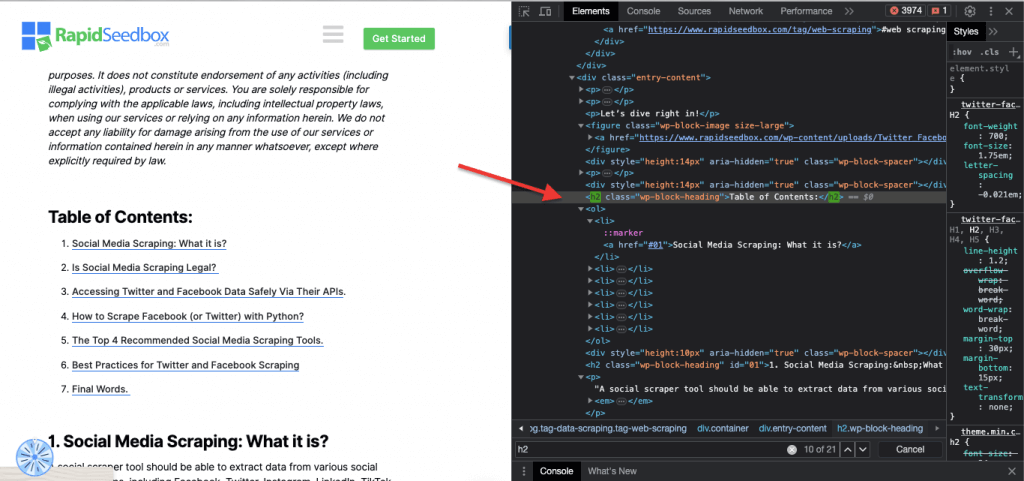
iii. Обмеження по посвідченню особи.
Обмеження ID допомагають вибрати HTML-елемент на основі його унікального атрибута ID. Атрибут ID використовується для однозначної ідентифікації окремого елемента на веб-сторінці. На відміну від класів, які можна використовувати для декількох елементів, ідентифікатори повинні бути унікальними в межах сторінки.
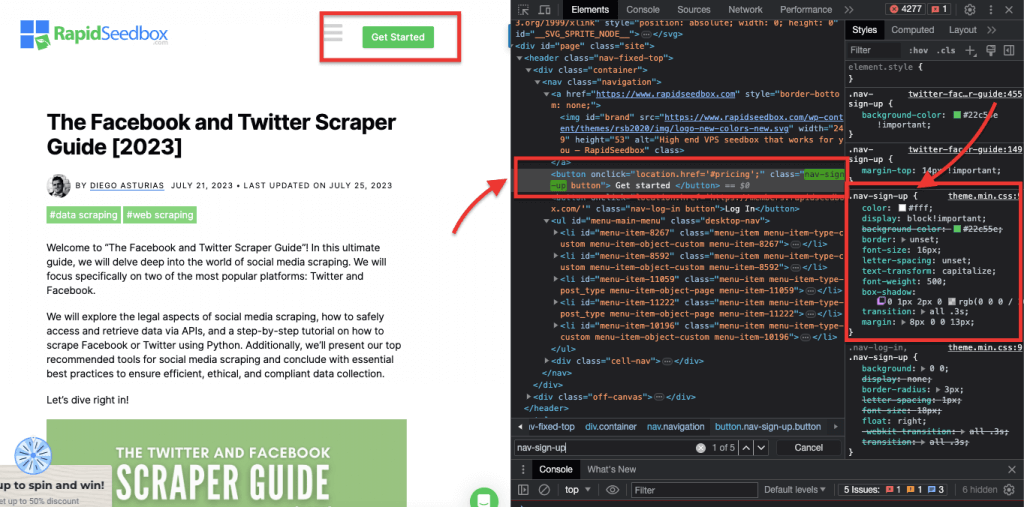
Приклад: CSS-селектор "#header" виділить елемент з атрибутом ID, встановленим у значення "header".


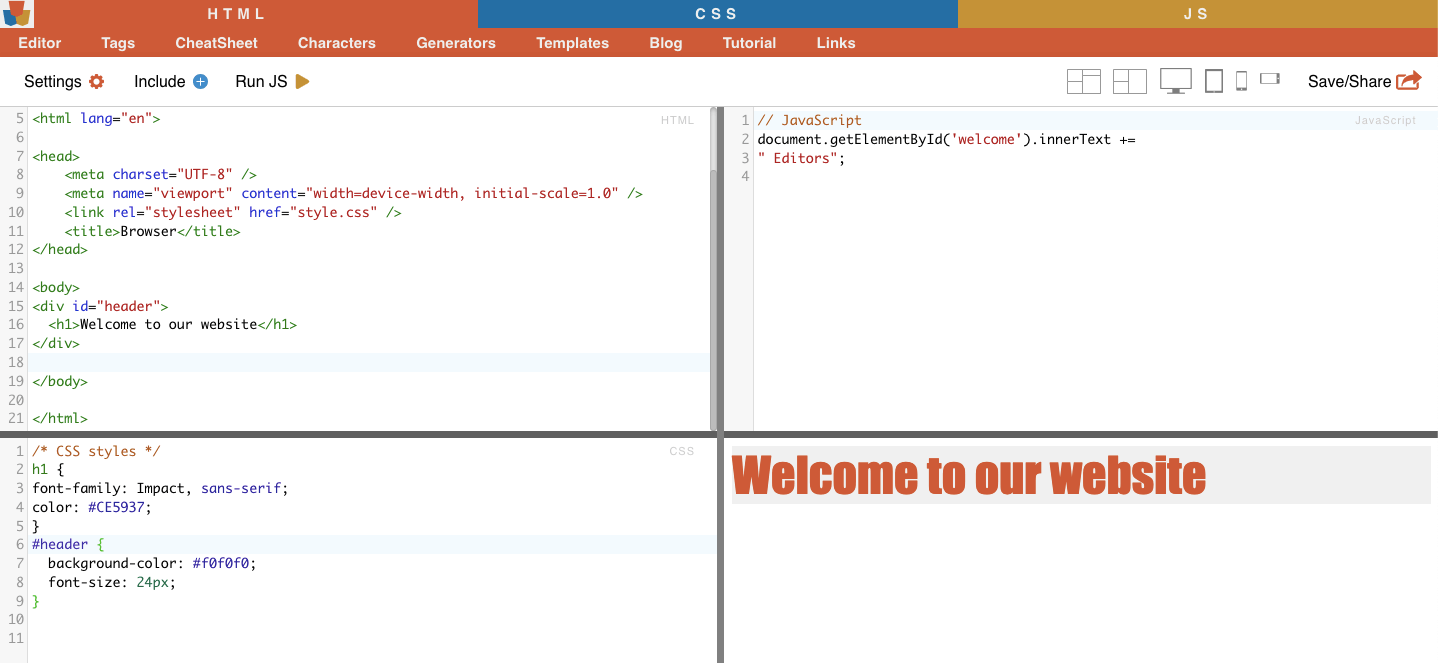
Приклад з реального життя: Пошук ідентифікаторів вручну. Після знаходження #01 вам потрібно знайти id="01″
iv. Зіставлення атрибутів.
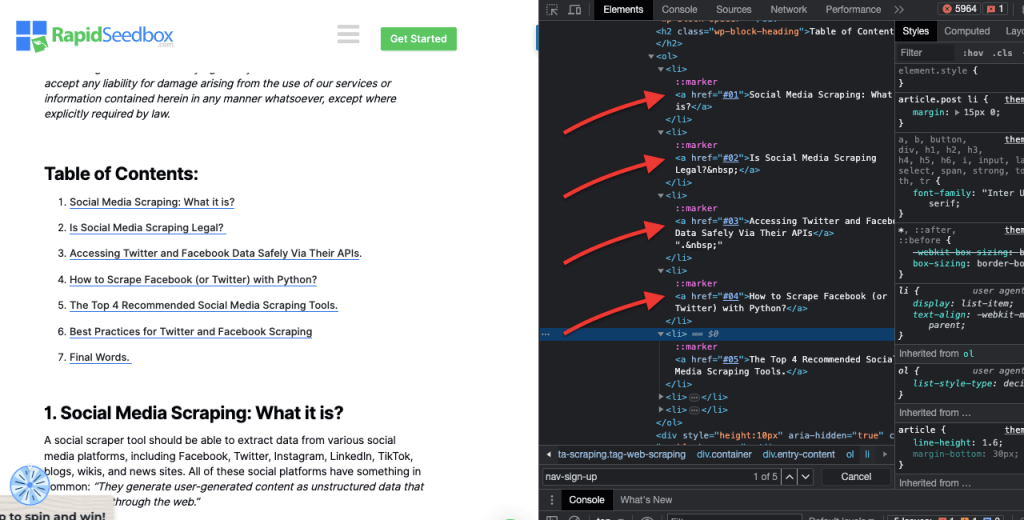
Цей метод передбачає відбір елементів HTML на основі певних атрибутів та їхніх значень. Це дозволяє вам вибирати елементи, які мають певний атрибут або значення атрибута. Існують різні типи зіставлення атрибутів, наприклад, точне зіставлення, зіставлення підрядків тощо.
Приклад: У наступному прикладі показано кастомний атрибут, який називається тип даних. Щоб націлити або стилізувати певні елементи (наприклад, елементи списку, позначені як "фрукти"), ви можете використовувати селектор CSS, який вибирає елементи на основі значень їхніх атрибутів.
Щоб вилучити лише елементи, позначені як "фрукти", ви можете використати наступний CSS-селектор:

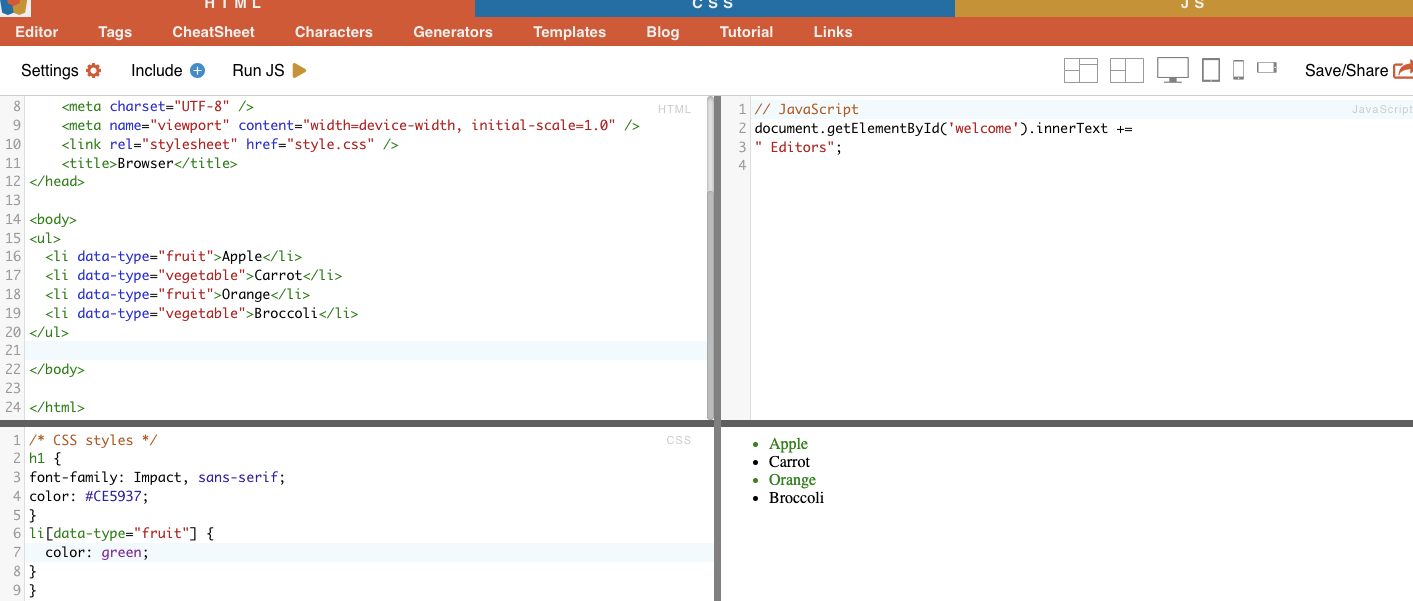
Приклад з реального життя: Ручний пошук атрибутів.
c. Xpath Selectors:
CSS-селектори ідеально підходять для простих завдань веб-скрепінгу, де структура HTML відносно проста. Але коли структура HTML стає більш заплутаною і складною, є інше рішення: селектори XPath.
Селектори XPath (селектори мови XML-шляхів) це гнучка мова шляхів, яка використовується для навігації по елементах XML або HTML-документа. Вони допомагають вибрати певні вузли в HTML-коді на основі розташування, імен, атрибутів або вмісту. Селектори XPath також можуть бути корисними для пошуку елементів на основі їхніх атрибутів класу та ідентифікатора.
Ось три приклади селекторів XPath для веб-скрепінгу.
i. Приклад 1: Вираз XPath: ' //a
Вираз XPath ' //a' вибирає всі елементи '' на сторінці, незалежно від їхнього розташування в документі. На наведеному нижче знімку екрана показано ручне визначення всіх елементів '' на сторінці.
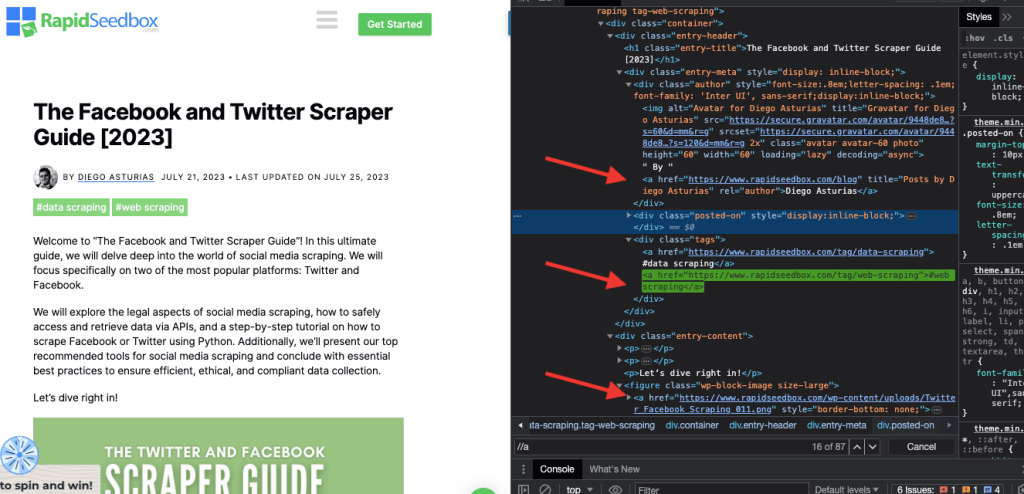
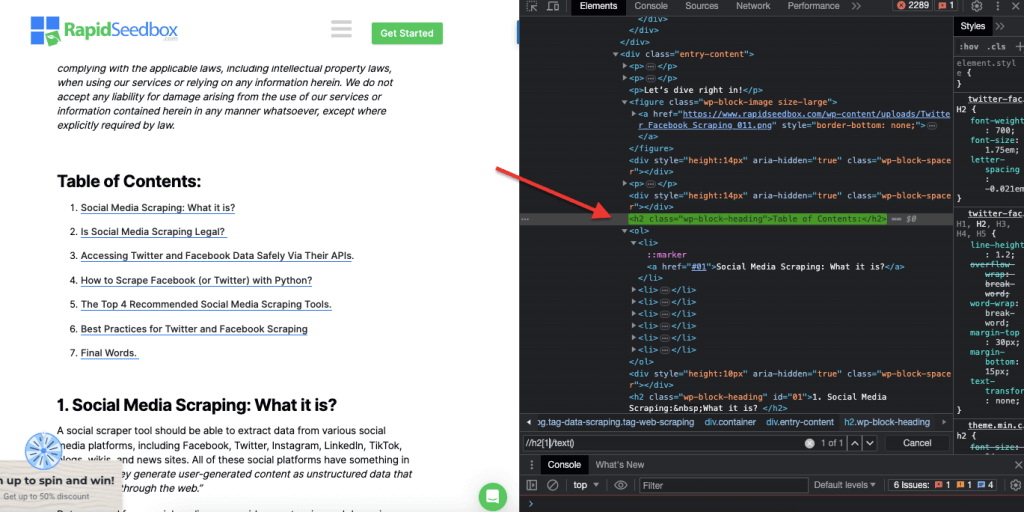
ii. Приклад 2: ' //h2[1]/text()'
Вираз XPath:
' //h2[1]/text() '
Буде вибрано текстовий вміст першого заголовка h2 на сторінці. Індекс ''1'' використовується для вказівки першого входження елемента h2, ви також можете вказати друге входження за допомогою індексу ''2'' і так далі. На наступному знімку екрана показано ручне визначення першого заголовка h2 на сторінці за допомогою цього селектора XPath.
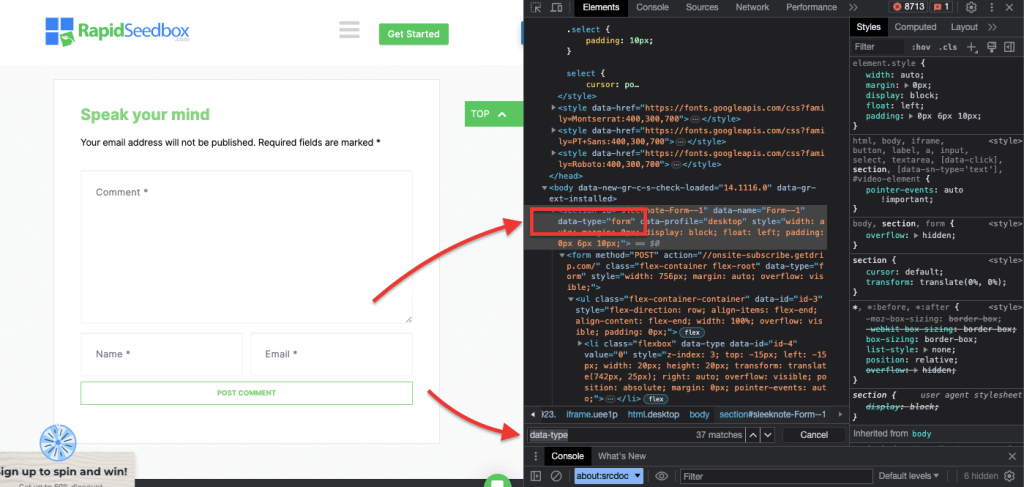
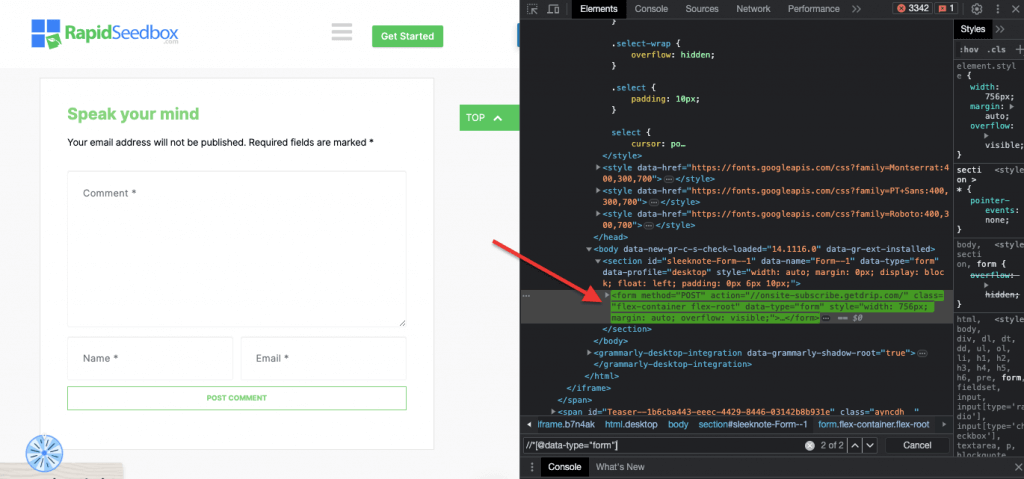
iii. Приклад 3. ' //* [@data-type="form"]'
Вираз XPath //* [@data-type="form"] вибирає всі елементи, які мають атрибут даних зі значенням "form". Метод * вказує на те, що буде вибрано будь-який елемент із зазначеним атрибутом даних, незалежно від імені його вузла. На наступному скріншоті показано процес ручного пошуку елементів зі значенням "form".
Візуальний огляд і вилучення даних вручну з HTML-сторінки за допомогою цих селекторів CSS і XPath може бути не тільки трудомістким, але й схильним до помилок. Крім того, ручне або візуальне вилучення даних абсолютно не підходить для великомасштабного збору даних або повторюваних завдань скрапінгу. Саме тут сценарії та програмування є дуже корисними.
Шукаєте надійні проксі-сервери для веб-скрепінгу?
Підвищіть ефективність веб-скрепінгу за допомогою високоякісних проксі-сервісів RapidSeedbox. Насолоджуйтесь швидким, безпечним та анонімним скрапінгом!
Які мови програмування найкраще підходять для веб-скрепінгу?
Найпопулярнішою мовою програмування для скрапінгу є Python завдяки своїм бібліотекам і пакетам (докладніше про це в наступному розділі). вискоблювання полотна - Rоскільки вона також має фантастичний набір підтримуваних бібліотек та фреймворків. Крім того, варто також згадати C# - популярну мову програмування, яку використовують багато веб-скрепери. Такі веб-сайти, як ZenRows, мають вичерпні посібники з як скрафтити веб-сайт у C#що полегшує розробникам розуміння процесу та створення власних проектів.
Для спрощення, цей посібник з веб-скрепінгу буде зосереджений на веб-скрепінгу за допомогою Python. Продовжуйте читати!
3. Веб-скрейпінг на Python (з кодом).
Навіщо візуально перевіряти і вручну витягувати дані HTML за допомогою селекторів CSS або XPath, якщо їх можна використовувати систематично і автоматично за допомогою мов програмування?
Існує багато популярних бібліотек і фреймворків для веб-скрейпінгу, які підтримують селектори CSS для полегшення вилучення даних. Однією з найпопулярніших мов програмування для веб-скрепінгу є Pythonдля своїх бібліотек, таких як BeautifulSoup, Запити, CSS-Select, Селені Скребок.. Ці бібліотеки дозволяють веб-скреперам використовувати селектори CSS і XPath для ефективного вилучення даних.
Прекрасний Суп.
BeautifulSoup - один з найпопулярніших і найпотужніших пакетів Python, призначений для розбору HTML і XML документів. Цей пакет створює дерево розбору сторінок, що дозволяє легко витягувати дані з HTML.
| Цікавий факт! У боротьбі з COVID-19, DXY-COVID-19-Crawler від Jiabao Lin використовував BeautifulSoup для вилучення цінних даних з китайського медичного веб-сайту. Це допомогло дослідникам відстежувати та розуміти поширення вірусу. [джерело: Tidelift] |
Прохання.
Python's Запити це проста, але потужна бібліотека HTTP. Вона корисна для створення HTTP-запитів для отримання даних з веб-сайтів. "Requests" спрощує процес надсилання HTTP-запитів та обробки відповідей у вашому Python-проекті веб-скрепінгу.
a. Підручник з веб-скрепінгу на Python (+ код)
У цьому підручнику з веб-скрепінгу за допомогою Python ми отримаємо дані з цільового HTML-сайту за допомогою коду Python з "запитами" і бібліотеки BeautifulSoup.
Передумови:
Переконайтеся, що виконані наступні передумови:
- Середовище Python: Переконайтеся, що у вас є Python встановлений на вашому комп'ютері. Також переконайтеся, що ви можете запустити скрипт у вашому улюбленому середовищі Python (наприклад, ХОЛОСТИЙ або Jupyter Notebook).
- Запити до бібліотеки: Встановіть
запитибібліотека. Використовується для надсилання HTTP GET-запитів на вказану URL-адресу. Встановити її можна за допомогоюпіпбігаючиЗапити на встановлення pipу командному рядку або терміналі. - Бібліотека BeautifulSoup: Встановіть
beautifulsoup4бібліотеку. Ви можете встановити її за допомогоюпіпбігаючиpip install beautifulsoup4у вашому терміналі.
Код на Python для веб-скрепінгу даних зі сторінки (w/ BeautifulSoup)
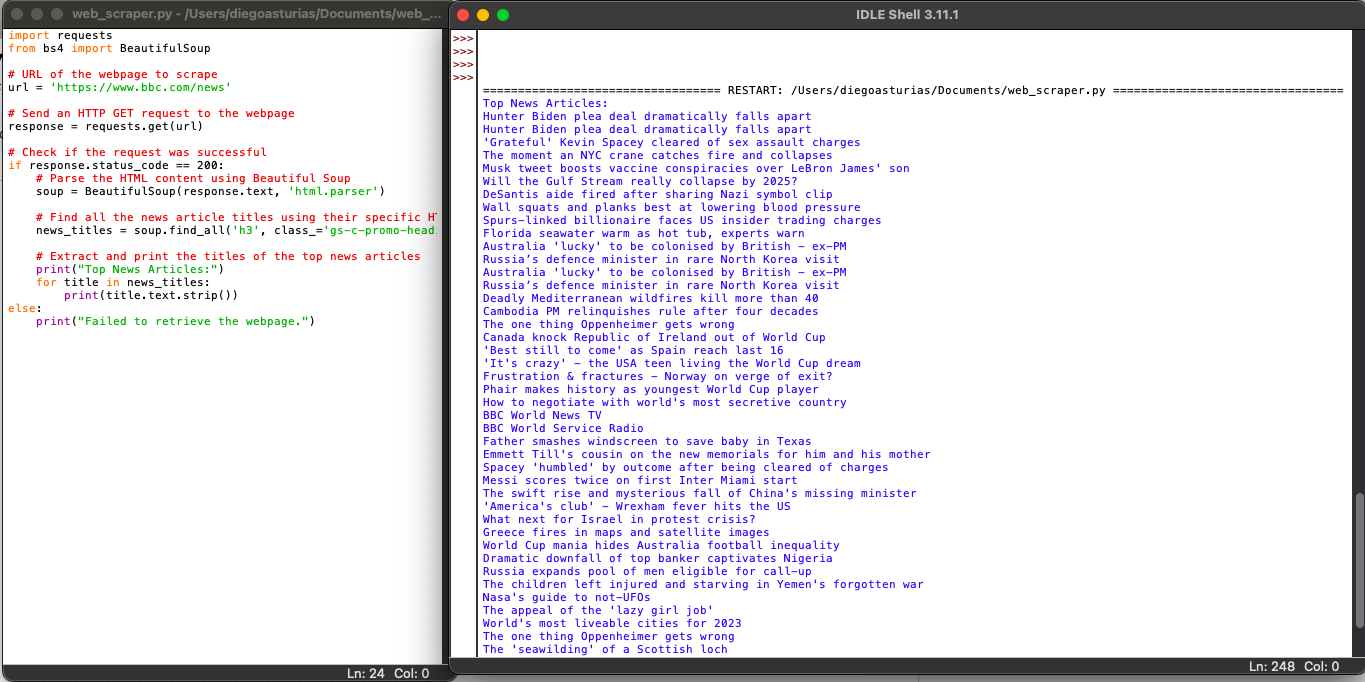
Наступний скрипт отримає вказану URL-адресу, розбере HTML-вміст за допомогою BeautifulSoup і виведе заголовки найпопулярніших новинних статей на веб-сторінці.

Під час запуску скрипта в IDLE Shell на екран виводяться всі зібрані "news_titles" з цільового веб-сайту.
b. Варіації нашого коду на Python для веб-скрепінгу.
Ми можемо взяти наш попередній код для веб-скрепінгу на Python і зробити кілька варіацій, щоб зіскребти різні типи даних.
Наприклад:
- Пошук зображень: Щоб знайти всі теги зображень (
) на сторінці, ви можете скористатися методом find_all() з ім'ям тегу 'img':

- Пошук посилань: Щоб знайти всі якірні теги (), які представляють посилання на веб-сторінці, можна скористатися методом find_all() з ім'ям тегу 'a':

Наданий скрипт (разом з варіаціями) є базовим скриптом веб-скрепінгу. Він просто витягує і друкує заголовки найпопулярніших новинних статей із вказаної URL-адреси. Але, на жаль, цьому простому скрипту бракує багатьох функцій, які складають більш комплексний проект веб-скрепінгу. Є кілька елементів, які ви можете розглянути, додаючи зберігання даних, обробку помилок, пагінацію/сканування, використання агентів користувача і заголовків, дроселювання і заходи ввічливості, а також можливість обробки динамічного контенту.
4. Чи законний веб-скрепінг?
Веб-скрепінг зазвичай сприймається як суперечливе або незаконне явище. Але насправді це легітимна практика, і якщо дотримуватися певних етичних і правових меж, веб-скрепінг є цілком законним.
Законність веб-скрепінгу залежить від характеру даних, що вилучаються, і методів, які використовуються. Веб-скрепінг вважається законним, якщо він використовується для збору загальнодоступної інформації з Інтернету. Однак завжди потрібно бути обережним, особливо коли маєш справу з персональними даними або контентом, захищеним авторським правом.
Ось кілька порад, про які варто пам'ятати:
- Не вилучайте приватні дані. Також незаконним є вилучення даних, які не є загальнодоступними. Вилучення даних за сторінкою входу в систему, де вказані логін і пароль, є незаконним у США, Канаді та більшості країн Європи.
- Те, що ви робите з даними, може призвести до неприємностей. Етичне використання веб-скрепінгу передбачає уважне ставлення до даних, що збираються, та їхнього призначення. Особливу увагу слід приділяти персональним даним та інтелектуальній власності. Переконайтеся, що ви дотримуєтеся таких нормативних актів, як GDPR і CCPA, які регулюють обробку персональних даних. Наприклад, повторне використання або перепродаж контенту чи завантаження матеріалів, захищених авторським правом, є незаконним (і цього слід уникати).
- Також важливо переглянути Умови надання послуг на веб-сайтах. Це документи, які вказують кожному, хто користується їхнім сервісом або контентом, як слід і як не слід взаємодіяти з ресурсами.
- Завжди передбачайте альтернативні варіанти, наприклад, використання офіційно наданих API. Деякі веб-сайти, такі як державні установи, погода та платформи соціальних мереж (Facebook і Twitter) роблять частину своїх даних доступними для громадськості через API.
- Подумайте про перевірку файлу robots.txt. Цей файл зберігається на веб-сервері і дає вказівки веб-сканерам і веб-скрепінгу про те, які частини веб-сайту слід уникати, а які - дозволені. Він також дає вказівки про обмеження швидкості.
- Уникайте ініціювання атак веб-скрепінгу. Залежно від контексту, іноді веб-скрепінг називають скрепінг-атакою. Коли спамери використовують ботнети (армії ботів) для націлювання на веб-сайт з великими і швидкими запитами, весь сервіс веб-сайту може вийти з ладу. Масштабне вилучення даних може призвести до падіння цілих сайтів.
Останні новини про юридичні аспекти веб-скрепінгу.
Нещодавні судові рішення роз'яснили, що вилучення загальнодоступних даних, як правило, не вважається порушенням. Знакове рішення апеляційного суду США підтвердило законність веб-скрепінгу, заявивши, що вилучення загальнодоступних даних в Інтернеті не порушує Закон про комп'ютерне шахрайство і зловживання (CFAA) [джерело]: TechCrunch].
До інших новин, нещодавні судові позови проти OpenAI та Microsoft підкреслюють занепокоєння щодо законів про конфіденційність, інтелектуальну власність та боротьбу з хакерством, згідно з останніми новинами за липень 2024 року [Блумберг]. Поки CFAA має обмежену ефективність, вивчаються позови про порушення контрактів і закони штатів про конфіденційність. Взаємодія між авторським правом і договірним правом залишається невирішеною, залишаючи багато питань без відповіді в контексті веб-скрепінгу.
В останніх новинах, [джерело: IndiaTimes] Ілон Маск змінює правила Twitter, щоб запобігти надмірному вилученню даних. За словами Маска, надмірне вилучення даних негативно впливає на користувацький досвід. Він припустив, що в цьому винні організації, які використовують великі мовні моделі для генеративного ШІ.
5. Як веб-сайти намагаються заблокувати веб-скрепінг?
Компанії хочуть, щоб деякі з їхніх даних були доступними для відвідувачів. Але коли компанії або користувачі використовують автоматизовані скрипти або ботів для агресивного вилучення даних з сайту, це може призвести до значного порушення конфіденційності та зловживання ресурсами на цільовому веб-сервері та сторінці. Такі сайти-жертви воліють стримувати такий тип трафіку.
Антискребкові техніки.
- Незвичайні та великі обсяги трафіку з одного джерела. Веб-сервери можуть використовувати WAF (брандмауери веб-додатків) з чорними списками шумних IP-адрес для блокування трафіку, фільтри на "незвичні" швидкості та розміри запитів, а також механізми фільтрації. Деякі сайти використовують комбінацію WAF і CDN (мережі доставки контенту), щоб повністю відфільтрувати або зменшити шум від таких IP-адрес.
- Деякі веб-сайти можуть виявляти шаблони перегляду, схожі на ботів. Подібно до попереднього методу, веб-сайти також блокують запити на основі User-Agent (HTTP-заголовку). Боти не використовують звичайний браузер. Ці боти мають різні рядки user-agent (наприклад, краулер, павук або бот), відсутність варіацій, відсутність заголовків (безголові браузери), швидкість запитів тощо.
- Веб-сайти також часто змінюють розмітку HTML. Боти для веб-скрепінгу слідують послідовним маршрутом "HTML-розмітки", переглядаючи вміст веб-сайту. Деякі веб-сайти регулярно і випадковим чином змінюють HTML-елементи в розмітці. Цей метод збиває бота зі звичного для нього маршруту або графіка скрапінгу. Зміна HTML-розмітки не зупиняє веб-скрепінг, але робить його набагато складнішим.
- Використання викликів на кшталт CAPTCHA. Щоб уникнути ботів, які використовують безголові браузери, деякі веб-сайти вимагають складних CAPTCHA-завдань. Ботам, які використовують безголові браузери, важко вирішувати такі завдання. CAPTCHA були створені для того, щоб їх можна було розгадати на рівні користувача (через браузер), а не роботів.
- Деякі сайти є пастками для скрап-ботів. Деякі веб-сайти створені лише для того, щоб ловити скрап-ботів - ця техніка називається "медові горщики". Ці "горщики" видимі лише для ботів-скреберів (а не для звичайних відвідувачів) і створені для того, щоб заманити веб-скреберів у пастку.
6. Етичні та найкращі практики для веб-скрепінгу.
Вишкрібання веб-сторінок має здійснюватися відповідально та етично. Як згадувалося раніше, прочитання Умов та положень (Terms and Conditions, або ToS) має дати вам уявлення про обмеження, яких ви повинні дотримуватися. Якщо ви хочете отримати уявлення про правила веб-сканера, перевірте його файл ROBOTS.txt.
Якщо веб-скрепінг повністю заборонений або заблокований, використовуйте їхній API (якщо він доступний).
Крім того, не забувайте про пропускну здатність цільового веб-сайту, щоб не перевантажувати сервер надто великою кількістю запитів. Автоматизація запитів зі швидкістю та правильними тайм-аутами, щоб уникнути навантаження на цільовий сервер, має вирішальне значення. Оптимальним варіантом є імітація користувача в режимі реального часу. Крім того, ніколи не вилучайте дані за сторінками входу в систему.
Дотримуйтесь правил, і все буде добре.
Найкращі практики веб-скрепінгу.
- Використовуй проксі. Проксі-сервер - це сервер-посередник, який перенаправляє запити. Під час веб-скрепінгу за допомогою проксі-сервера ви перенаправляєте свій початковий запит через нього. Таким чином, проксі зіставляє запит зі своєю IP-адресою і перенаправляє його на цільовий веб-сайт. Використовуйте проксі, щоб:
- Усуньте ймовірність потрапляння вашої IP-адреси до чорного списку або блокування. Завжди робіть запити через різні проксі-сервери Проксі-сервери IPv6 є гарним прикладом. Проксі-пул може допомогти вам виконувати запити великого обсягу без блокування.
- Оминайте географічно орієнтований контент. Проксі в певному регіоні корисний для вилучення даних відповідно до конкретного географічного регіону. Це корисно, коли веб-сайти та служби знаходяться за CDN.
- Ротаційні проксі. Ротаційні проксі беруть (обертають) новий IP з пулу для кожного нового з'єднання. Майте на увазі, що VPN не є проксі-серверами. Хоча вони роблять щось дуже схоже - забезпечують анонімність, вони працюють на різних рівнях.
- Поворот UA (User Agents) та заголовки HTTP-запитів. Щоб обертати UA і HTTP-заголовки, вам потрібно зібрати список рядків UA з реальних веб-браузерів. Помістіть цей список у код веб-скрепінгу на Python і налаштуйте запити на вибірку випадкових рядків.
- Не виходьте за рамки. Зменшуйте кількість запитів, робіть ротацію та рандомізуйте. Якщо ви робите велику кількість запитів на сайт, почніть з рандомізації. Зробіть так, щоб кожен запит виглядав випадковим і схожим на людський. По-перше, змініть IP-адресу кожного запиту за допомогою ротаційних проксі-серверів. Також використовуйте різні HTTP-заголовки, щоб виглядало так, ніби запити надходять з інших браузерів.
7. FAQ по веб-скрепінгу: Поширені запитання.
a. Що таке robots.txt і яку роль він відіграє у веб-скрепінгу?
Технологія robots.txt слугує інструментом комунікації між власниками веб-сайтів, пошуковими роботами та "скреперами". Це текстовий файл, розміщений на сервері веб-сайту, який містить інструкції для веб-роботів (пошукових роботів, веб-павуків та інших автоматизованих ботів) про те, до яких частин веб-сайту їм дозволено мати доступ і сканувати, а яких частин їм слід уникати. "Добре виховані" веб-сканери (наприклад, Googlebot) призначені для автоматичного читання файлу robots.txt. Скрепери не призначені для читання цього файлу. Тому знання robots.txt дуже важливе для того, щоб поважати побажання власника веб-сайту.
b. Які методи використовують адміністратори веб-сайтів, щоб уникнути "зловмисних" або "несанкціонованих" спроб веб-скрепінгу?
Не всі скрепери видобувають дані етично і законно. Вони не дотримуються Умов користування сайтом (TOS) або інструкцій robots.txt. Тому адміністратори сайтів можуть вживати додаткових заходів для захисту своїх даних і ресурсів, наприклад, використовувати блокування IP-адрес або підробку CAPTCHA. Вони також можуть використовувати заходи з обмеження швидкості, верифікацію користувача-агента (для виявлення потенційних ботів), відстежувати сесії, використовувати автентифікацію на основі токенів, використовувати CDN (мережі доставки контенту) або навіть використовувати системи виявлення, засновані на поведінці.
c. Веб-скребінг проти веб-краулінгу?
Хоча веб-скрепінг і веб-краулінг є методами вилучення веб-даних, вони мають різні цілі, сферу застосування, автоматизацію та правові аспекти. З одного боку, методи веб-скрепінгу спрямовані на вилучення конкретних даних на конкретних сайтах. Вони цілеспрямовані та мають певну обмежену сферу застосування. Веб-скрепінг використовує автоматизовані скрипти або сторонні інструменти для запиту, отримання, аналізу, вилучення та структурування даних. Методи веб-сканування, з іншого боку, використовуються для систематичного пошуку в Інтернеті. Вони популярні серед пошукових систем (ширшого масштабу), платформ соціальних мереж, дослідників, агрегаторів контенту тощо. Веб-сканери можуть автоматично відвідувати багато сайтів (за допомогою ботів, пошукових роботів або павуків), створювати список, індексувати дані (створювати копії) і зберігати їх у базі даних. Зазвичай вони перевіряють файли ROBOTS.txt.
d. Інтелектуальний аналіз даних vs вилучення даних: У чому їхні відмінності та схожість?
І інтелектуальний аналіз даних, і вилучення даних передбачають вилучення даних. Однак інтелектуальний аналіз даних зосереджується на використанні статистичних методів і методів машинного навчання для аналізу структурованих наборів даних. Він спрямований на виявлення закономірностей, взаємозв'язків та інсайтів у великих і складних структурованих наборах даних. Вилучення даних, з іншого боку, зосереджене на "частині збору" конкретної інформації з веб-сторінок і веб-сайтів. Обидва методи та інструменти можна використовувати разом. Вилучення даних може бути попереднім етапом збору даних з Інтернету, які потім подаються в алгоритми інтелектуального аналізу даних для поглибленого аналізу та виявлення інсайтів.
e. Що таке скрейпінг екрану? І як він пов'язаний з вилученням даних?
Обидва методи зосереджені на вилученні даних, але відрізняються за типом даних, які вони вилучають. Вишкрібання сита Ці інструменти призначені для "автоматичного" захоплення та вилучення візуальних даних, що відображаються на веб-сайтах і в документах, включно з екранним текстом. На відміну від веб-скрепінгу, який аналізує дані з HTML (таким чином витягуючи широкий спектр веб-даних), скріпінг екрану зчитує текстові дані безпосередньо з екрану.
f. Чи є веб-збирання тим самим, що й веб-скребкування?
Вилучення даних і збір веб-даних тісно пов'язані між собою і часто використовуються як взаємозамінні поняття, але це не одне й те саме. Збір даних в Інтернеті має ширше значення. Воно охоплює різні методи вилучення даних з Інтернету, в тому числі різні автоматичні механізми вилучення даних з Інтернету, такі як веб-скребінг. Чіткою відмінністю є те, що збір даних часто використовується, коли задіяний API, а не прямий синтаксичний аналіз HTML-коду з веб-сторінок (як у випадку зі скрайбінгом).
g. CSS Selector vs xPath Selector: Які відмінності при скрепінгу?
CSS-селектори - це ефективний спосіб вилучення даних під час веб-скрепінгу. Вони мають простий синтаксис і добре працюють у більшості сценаріїв вилучення. Однак у більш складних випадках або при роботі з вкладеними структурами, селектори Xpath можуть забезпечити додаткову гнучкість і функціональність.
h. Як працювати з динамічними веб-сайтами за допомогою Selenium?
Selenium - це потужний інструмент для веб-скрепінгу динамічних веб-сайтів. Він дозволяє взаємодіяти з елементами на веб-сторінці так, як це робив би користувач. Ця можливість дозволяє вашому "скрипту" переміщатися по динамічно згенерованому контенту. Використовуючи WebDriver від Seleniumви можете чекати на завантаження елементів сторінки, взаємодіяти з елементами AJAX і витягувати дані з веб-сайтів, які значною мірою покладаються на JavaScript.
i. Як працювати з AJAX та JavaScript під час веб-скрепінгу?
При роботі з AJAX і JavaScript під час веб-скрепінгу традиційних бібліотек, таких як Requests і Beautiful Soup, може бути недостатньо. Для обробки AJAX-запитів і JavaScript-вмісту можна використовувати такі інструменти, як Selenium або безголові браузери, такі як Лялькар.
Шукаєте надійні проксі-сервери для веб-скрепінгу?
Підвищіть ефективність веб-скрепінгу за допомогою високоякісних проксі-сервісів RapidSeedbox. Насолоджуйтесь швидким, безпечним та анонімним скрапінгом!
8. Висновок.
Вітаємо! Ви завершили найкращий посібник зі скрапінгу!
Ми сподіваємося, що цей посібник озброїв вас знаннями та інструментами для використання потенціалу веб-скрепінгу у ваших проектах.
Пам'ятайте, що з великою владою приходить велика відповідальність. Починаючи свій шлях у веб-скрепінгу, завжди віддавайте перевагу етичним практикам, поважайте умови надання послуг на веб-сайтах і пам'ятайте про конфіденційність даних.
Ми торкнулися лише верхівки айсберга. Веб-скрепінг може бути досить об'ємною темою. Але ж ви вже скрафтили веб-сайт!
Безперервне навчання та постійне ознайомлення з новітніми технологіями та правовими змінами дозволять вам орієнтуватися в цьому складному світі.
0Коментарі