XPath is a powerful query language used for selecting nodes from XML documents.
The following XPath Cheat Sheet is a shortened reference that covers everything you need about XPath, from its syntax, functions, and operators, to usage in automation testing with Selenium.
You can use this cheat sheet to remember about XPath expressions, selectors, common issues, troubleshooting tips, and best practices.

Table of Contents:
- Overview of XPath
- XPath Syntax and Basic Concepts
- XPath Functions, Operators, and Axes
- XPath Queries and Selectors
- XPath in Automation Testing with Selenium
- XPath FAQ
- Final Words.
1. Overview of XPath
XPath (XML Path) language, is a query language used for selecting nodes from XML documents. It allows you to navigate through elements and attributes in an XML document. Additionally, XPath is quite a big deal for applications such as web scraping, data extraction, and automation testing, particularly with tools like Selenium.
XPath is also essential in web development for DOM (Document Object Module) manipulation and retrieving data dynamically. Plus, thanks to its precise selection capabilities, developers can use XPath to extract structured data from web pages (even from the most complex structures).
| A reminder: An XML document forms a structured tree-like arrangement that includes elements, attributes, and text content. XPath uses this structure to navigate through al the document’s nodes in the most efficient way. |
2. XPath Syntax and Basic Concepts
In XPath, everything is considered a node. These include elements, attributes, text, namespaces, and the document’s root. Understanding these nodes is key to using XPath.
XPath Expressions: These specify paths from one part of an XML document to another. They harness the tree-like structure to pinpoint exact locations.
a. Basic Syntax: Root, Current Node, Parent, and Attribute Selectors
| Element | Syntax | Description |
| Root Node | / | Starts the selection from the root of the document. |
| Current Node | . | Represents the node currently being processed. |
| Parent Node | .. | Selects the parent of the current node. |
| Attribute | @ | Used to select attributes of elements. |
- Root selector (/): In XPath, when you see a single slash / at the beginning of an expression, it means that the path starts from the root node of the document.
- Example: /bookstore/book – This XPath expression selects all <book> elements that are children of the root <bookstore> element.
- Current node (.): Represents the current node being processed.
- Example: Suppose we are currently focused on a <book> element, the following XPath would select the current <book>: .
- Parent node (..): Navigates to the parent of the current node.
- Example: If the current node is <price>, the following XPath would select its parent element: ../title
- Attribute selectors (@): Used to select attributes. To select the value of an attribute, use @.
- For example: Use @ to select the value of the category attribute from the <book> element: /bookstore/book/@category.
b. Basic Structure of XPath Expressions
An XPath expression generally follows the pattern: axisname::nodetest[predicate]. This allows for fine-tuned selections (of XML nodes) based on specific criteria.
- axisname: Direction for the search (e.g., child, ancestor).
- nodetest: The node type or name to match (e.g., book).
- predicate: Additional criteria for the match (e.g., [price>35]).
Here’s an XPath example to clarify this syntax:
child::book[price>35.00]
In the above example, the XPath expression selects all the book children of the current node that have a price child node with a value greater than 35.00.
c. Differences Between Absolute and Relative XPath Expressions
- Absolute XPath: Begins with the root node (/) and defines a path from there to the desired element.
- Example: /bookstore/book/price — This selects all <price> elements exactly within <book> within <bookstore>. The path starts from the root and doesn’t depend on the current node context.
- Relative XPath: Starts from the current node context (//) and searches for the pattern anywhere in the document.
- Example: //price — This selects all <price> elements anywhere in the document, regardless of their exact location in the DOM tree. It’s useful when the structure of the XML document is unknown or may change.
| ‘//’ vs ‘/’ selectors? These selectors are essential for navigating XML in tasks like data extraction and web scraping. On the one hand, //: Selects elements matching a pattern anywhere, e.g., //div for all <div> elements. On the other hand, /: Targets only direct children, e.g., /html/body/div for <div> directly under <body>. |
d. Hands-on Example.
The following image shows an XML document with a basic structure. The XML content presented in this image displays a list of books, each with various elements such as author, title, genre, price, publish_date, and description. Each book is encapsulated within a book element that has an attribute id.
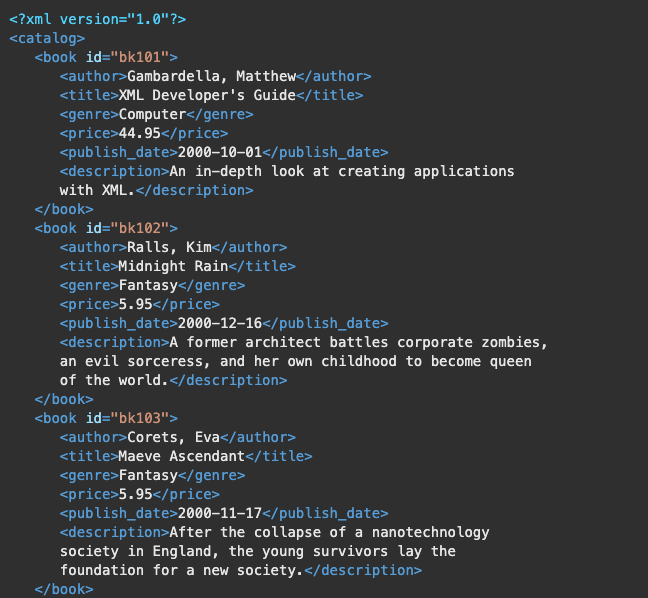
How would you use XPath in this XML Document?
- Root Selector (/): The root element is catalog. To select the entire catalog, the XPath would be /catalog.
- Current Node (.): When focused on a particular book node, the character: . would refer to that specific book element.
- Parent Node (..): For an element within a book element, such as title, .. would navigate up to the book parent element.
- Attribute Selectors (@): To select the id attribute of a book, the XPath would be /catalog/book/@id.
The Basic Structure of XPath Expressions:
- An expression to find a specific book by ID would look like this: /catalog/book[@id=’bk101′].
- To find the title of the first book: /catalog/book[1]/title.
- To find prices of all books greater than $10: /catalog/book[price>10]/price.
Boost web scraping with XPath and Rapidseedbox proxies
? Stay anonymous.
? Access restricted sites.
? Scale data handling.
? Target specific locations.
⏳ Avoid blocks.
———
3. XPath Functions, Operators, and Axes
XPath Functions, Operators, and Axes are fundamental components of XPath. Together, they enable precise XPath expressions for querying XML documents.
- Functions: Process XML nodes and values.
- Operators: Combine conditions and filter nodes.
- Axes: Define navigation direction in XML hierarchy.
| Function/Operator | Syntax | Description |
| contains() | contains(@attr, ‘value’) | Checks if attribute contains a specified value. |
| text() | text() | Selects the textual content of the current node. |
| and | A and B | Logical AND operator, combining two conditions. |
| or | A or B | Logical OR operator, combining two conditions. |
a. Commonly Used XPath Functions
- contains(): Checks if a node contains a specific text.
- Example: Select all books where the title contains the word “Guide”: //book[contains(title, ‘Guide’)]
- text(): Selects the textual content of a node.
- Example: Select all books where the text of the genre element is exactly “Fantasy”: //book[genre/text() = ‘Fantasy’]
- name(): Retrieves the name of a node.
- Example: Find the name of the first element within the first book node: name(/catalog/book[1]/*[1])
b. Logical Operators: and, or, not
These operators are used within predicates to combine multiple conditions.
- ‘and’ Operator:
- Example: Select all books that are in the “Fantasy” genre and priced below $10: //book[genre=’Fantasy’ and price<10]
- ‘or’ Operator:
- Example: Select all books that have either “Guide” or “Rain” in their titles: //book[contains(title, ‘Guide’) or contains(title, ‘Rain’)]
- ‘not’ Operator:
- Example: Select all books that do not belong to the “Computer” genre: //book[not(genre=’Computer’)]
c. Overview of Different XPath Axes
- Child: Selects all children of the current node.
- Example: Select all author elements that are children of book elements: //book/child::author
- Descendant: Selects all descendants (children, grandchildren, etc.) of the current node.
- Example: Select all price elements anywhere under a book element: //book/descendant::price
- Ancestor: Selects all ancestors (parent, grandparent, etc.) of the current node.
- Example: From a price element, select the book element it is within: //price/ancestor::book
- Following-sibling: Selects all siblings after the current node.
- Example: Select the next book element following the current book in the same level of the hierarchy: //book/following-sibling::book[1]
| Help! Abbreviated Syntax for XPath Expressions: Abbreviations like //para instead of /descendant::para simplify the expressions and enhance readability. |
4. XPath Queries and Selectors.
a. XPath Queries:
XPath queries are like the search terms used to navigate through and find specific parts of an XML document, which include elements, attributes, and text. These queries are essential for tasks like data extraction in web scraping or identifying web elements for automation testing. An example is: //input[@type=’text’ and @name=’email’]
To construct XPath queries, you need: Axes, Node Test, Predicates, Operators, and Functions (all of which we discussed previously). These elements work together to form expressions that precisely locate and select the data you need from an XML document.
Examples of Practical XPath Queries:
- To find an element with a specific id: //*[@id=’userID’]
- To select links within a specific section of a page: //div[@id=’navigation’]//a
- To find elements that contain a specific substring in their text: //*[contains(text(), ‘Welcome’)]
- To select all checkboxes that are checked: //input[@type=’checkbox’ and @checked=’checked’]
- To select the first item in a list: //(ul/li)[1]
- To select elements with a title attribute starting with ‘data’: //*[@title[starts-with(., ‘data’)]]
| Help! Using XPath with Namespaces: When dealing with XML documents that include namespaces, XPath queries must reference these namespaces appropriately to accurately select nodes. |
b. The XPath Selectors:
XPath Selectors identify and select different parts of an XML or HTML document, such as elements and attributes. These work based on hierarchical position or content. For example, //p selects all paragraph elements, and //a/@href selects the href attribute of anchor elements.
| Selector | Syntax | Use Case |
| All p elements | //p | Selects all <p> elements in the document. |
| Href attributes | //a/@href | Selects the href attribute of anchor elements. |
| First child | /parent/child[1] | Selects the first child under each specified parent. |
Examples of XPath Selectors:
- To select all span elements within div elements: //div//span
- To select all div elements with a class of ‘active’: //div[contains(@class, ‘active’)]
- To select the href attribute of all links with a rel attribute ‘nofollow’: //a[@rel=’nofollow’]/@href
- To select all img elements where the alt attribute is not empty: //img[@alt!=”]
- To select the next sibling of an element with an id ‘info’: //*[@id=’info’]/following-sibling::*[1]
- To select all input elements except for buttons: //input[not(@type=’button’)]
5. XPath in Automation Testing with Selenium.
a. Setup and Basic Examples
XPath expressions are commonly used in Selenium to locate elements on a web page that need to be interacted with, like clicking a button or inputting data. When using Selenium for automation testing, XPath allows you to accurately pinpoint and interact with various elements on a webpage.
Here are a few examples of how XPath is applied:
- Finding and clicking a login button:
|
1 2 |
login_button = driver.find_element_by_xpath("//button[@id='login']") login_button.click() |
- Entering text into a search box:
|
1 2 |
search_box = driver.find_element_by_xpath("//input[@name='q']") search_box.send_keys("XPath in Selenium") |
- Selecting a checkbox:
|
1 2 |
checkbox = driver.find_element_by_xpath("//input[@type='checkbox' and @value='subscribe']") checkbox.click() |
- Getting text from a specific element:
|
1 |
message_text = driver.find_element_by_xpath("//div[@class='message']").text |
b. Common Issues and Troubleshooting Tips
Working with XPath in Selenium might bring about several challenges, especially with dynamic content or complex web page structures like iframes.
Here are some tips to address these issues:
- Dynamic content: When elements have IDs or classes that change, use more stable attributes or relative XPath to locate these elements.
- Example:
|
1 2 |
# If the ID changes, use a part of the ID that remains constant or another attribute dynamic_element = driver.find_element_by_xpath("//div[contains(@id,'message-')]") |
- Handling iframes: You must switch to the iframe before interacting with elements within it.
- Example:
|
1 2 3 4 5 6 7 8 |
# First, switch to the iframe iframe = driver.find_element_by_xpath("//iframe[@id='login-frame']") driver.switch_to.frame(iframe) # Now interact with elements inside the iframe login_field = driver.find_element_by_xpath("//input[@id='username']") login_field.send_keys("user@example.com") # Don't forget to switch back to the main document driver.switch_to.default_content() |
- Elements not found: Ensure the page is fully loaded or use explicit waits to wait for an element to become available.
- Example:
|
1 2 3 4 5 |
from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.XPATH, "//div[@class='content']")) |
6. XPath FAQ.
1. What legal and ethical considerations should I remember when using XPath for web scraping?
Always respect copyright laws and website terms of service when scraping data. Avoid accessing protected or sensitive information without permission, and ensure your scraping activities do not harm the website’s functionality or burden its infrastructure. It’s advisable to use a proxy service when scraping data. For a better understanding of this topic, check our full guide to web scraping and its ethical considerations.
2. How can I practice XPath queries effectively?
Engage in exercises such as extracting specific data from online sources or manipulating local XML files using XPath. Some excellent practice scenarios could include retrieving news headlines from a news website or extracting product information from e-commerce sites.
3. What are the key enhancements in XPath 2.0 and 3.0 compared to XPath 1.0?
XPath 2.0 and 3.0 introduce advanced functions like ‘if’ expressions, quantified expressions, and improved conditional constructs. These versions support richer data types including dates, times, and durations, and allow for returning sequences instead of just node sets.
4. What common challenges might I encounter with XPath, and how can I address them?
Frequent challenges with XPath might include dealing with dynamically changing DOMs, handling namespaces, and managing elements that may not be visible on the page. What can you do to solve this? You could use more flexible XPath expressions, incorporate namespace management, and also use Selenium or similar tools to interact with dynamic content.
5. What is the difference between XPath and CSS selectors for selecting elements in HTML documents?
On the one hand, XPath allows for more complex queries, including selecting elements based on content, position, or condition. Plus, it can navigate the document in any direction (up, down, sideways). CSS selectors, on the other hand, are typically used for simpler, more direct queries, focusing on styling elements. Plus CSS selectors are limited to selecting elements based on their attributes, classes, and IDs.
6. What are some best practices for using XPath in HTML documents to improve performance?
To improve performance when using XPath in HTML documents, we recommend you use precise paths to avoid unnecessary traversals. In addition, also consider relative paths that are less likely to break with UI changes. Likewise, avoid using //* which searches the entire document, which will potentially slow down the query.
7. How can you handle dynamic web elements with XPath in Selenium?
When dealing with dynamic web elements in Selenium, is more effective to use XPath which relies on stable attributes or relationships rather than positions. Techniques could include using XPath functions, selecting stable elements, and implementing waits.
7. Final Words
XPath is the tool you need to guide you through the complexities of XML documents. This query language provides a precise path to navigate and select nodes.
We hope this XPath cheat sheet has equipped you with the knowledge to harness XPath effectively, whether you’re scraping the web or automating tests with Selenium.
0Comments