If you ever used Puppeteer, you might be familiar with JavaScript. But if have you ever wondered how to use Puppeteer on Python, then it is likely that you are looking for Pyppeteer.
Pyppeteer is the unofficial Python port of Puppeteer. It is a Node library designed for controlling headless Chrome or Chromium browsers.
In this comprehensive guide, we will delve into Pyppeteer’s features, including installation, setup, and usage for web scraping, automated testing, and performance monitoring. Additionally, we will explore the differences between Puppeteer and Pyppeteer. In the last sections, we provide a few troubleshooting tips, solutions to common issues, and best practices for reliable automation.
So, no more waiting… let’s dive in!

Disclaimer: This material has been developed strictly for informational purposes. It does not constitute endorsement of any activities (including illegal activities), products or services. You are solely responsible for complying with the applicable laws, including intellectual property laws, when using our services or relying on any information herein. We do not accept any liability for damage arising from the use of our services or information contained herein in any manner whatsoever, except where explicitly required by law.
Table of Contents
- Introduction to Pyppeteer
- Overview
- Popular Use Cases
- Differences between Puppeteer and Pyppeteer
- Installing and Setting Up Pyppeteer
- Prerequisites and Installation Steps
- Setting up the Environment
- Configuring Pyppeteer with Chromium
- Verifying the Installation
- Basic Usage of Pyppeteer
- Launching a Headless Browser
- Navigating to Web Pages
- Taking Screenshots
- Extracting Page Content
- Advanced Features of Pyppeteer
- Example Scripts
- Scrape Data from Web Page
- Working with Proxies
- Troubleshooting Common Issues
- Debugging Tips
- Handling Browser Errors
- Common Errors and Fixes
- Pyppeteer: FAQ
- Final Words
1. Introduction to Pyppeteer
Pyppeteer is an unofficial Python port for the Puppeteer JavaScript library, designed (specifically for developers) to automate Chrome/Chromium browsers. It provides a high-level API to interact with web pages, allowing interaction with page elements and extraction of information.
This Python port helps control the headless browser for web scraping, automated testing, and more. Although it can be used for various projects, it is trendy for web scraping, where dynamic content needs to be accessed and extracted from JavaScript-heavy websites.
Pyppeteer’s Official GitHub Project Repository
Popular Use Cases for Pyppeteer
- Web Scraping: Extracting data from websites, especially those with dynamic content.
- Automated Testing: Testing web applications by simulating user interactions and verifying UI elements.
- Screenshot and PDF Generation: Capturing screenshots of web pages or generating PDFs for documentation purposes.
- Performance Monitoring: Measuring page load times and performance metrics.
What are the differences between Puppeteer and Pyppeteer?
Pyppeteer aims to replicate the Puppeteer API. But still, there are significant differences that you need to be aware of. Such differences exist because of the distinct nature between Python and JavaScrip.
Comparison Table: Puppeteer vs. Pyppeteer
| Feature/Aspect | Puppeteer | Pyppeteer |
| Language | JavaScript | Python |
| Options Passing | Uses objects (JavaScript dictionaries) | Accepts both dictionaries and keyword arguments |
| Element Selectors | $, $$, $x | Page.querySelector(), Page.querySelectorAll(), Page.xpath() Shorthand: Page.J(), Page.JJ(), Page.Jx() |
| Page.evaluate() | Takes JavaScript functions or expressions as strings | Takes string representations of JavaScript functions or expressions “force_expr=True” for explicit expression evaluation |
| Installation | npm install puppeteer | pip install pyppeteer “pip install -U” git+https://github.com/pyppeteer/pyppeteer@dev |
| Use Cases | Web Scraping, Automated Testing, Screenshot and PDF Generation, Performance Monitoring | Web Scraping, Automated Testing, Screenshot and PDF Generation, Performance Monitoring |
| Execution Environment | Requires Node.js | Requires Python 3.8+ |
| Headless Browser | Chrome/Chromium | Chrome/Chromium |
| Community and Maintenance | Actively maintained by Google | Unmaintained, suggested to use Playwright as an alternative |
2. Installing and Setting Up Pyppeteer
a. Prerequisites and Installation Steps
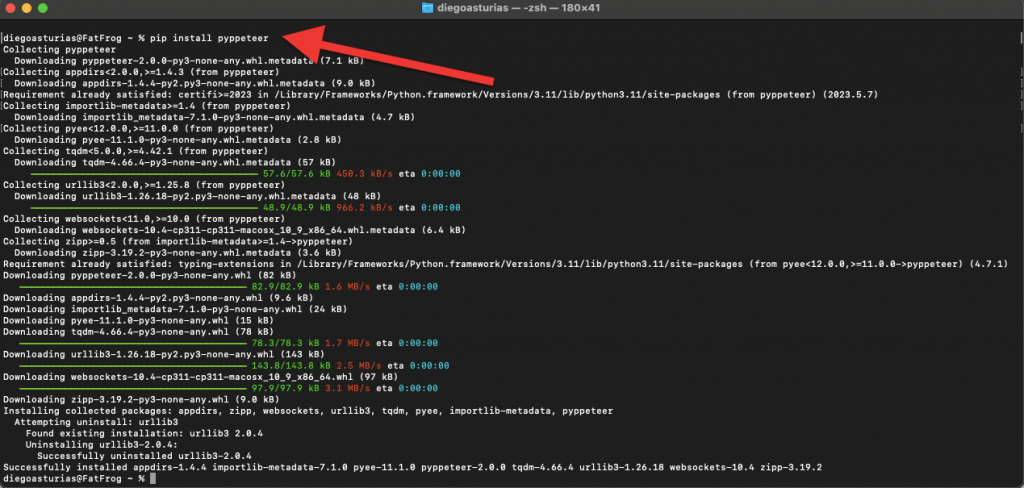
Pyppeteer requires Python 3.8 or higher. You can install it via pip from PyPI or directly from the GitHub repository for the latest version.
- Install from PyPI:
|
1 |
pip install pyppeteer |
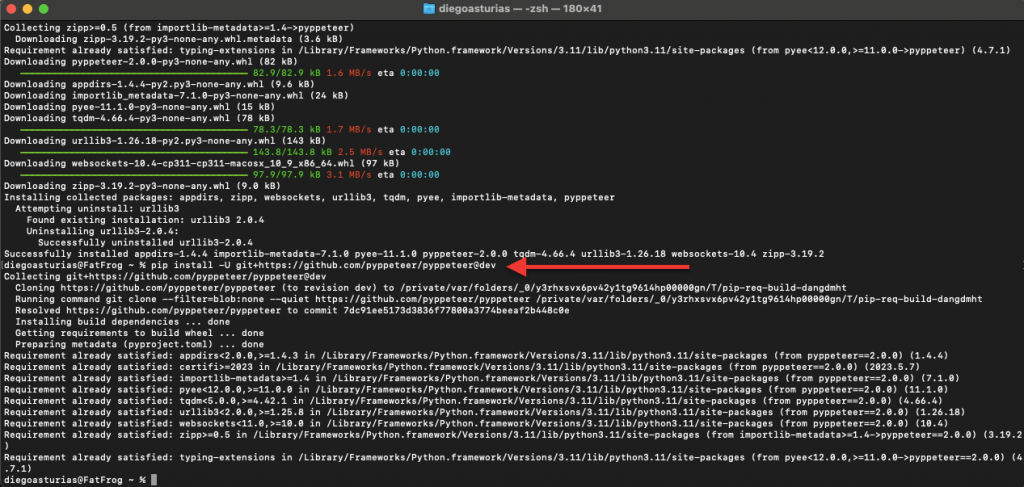
- Install the Latest Version from GitHub:
|
1 |
pip install -U git+https://github.com/pyppeteer/pyppeteer@dev |
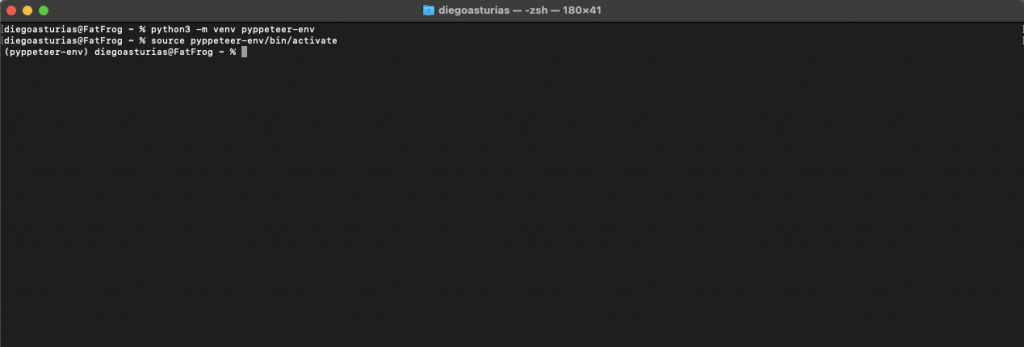
b. Setting up the Environment
As mentioned before, ensure that you have Python 3.8 or higher installed. It’s also recommended to create a virtual environment to manage all dependencies:
|
1 2 |
python3 -m venv pyppeteer-env source pyppeteer-env/bin/activate |
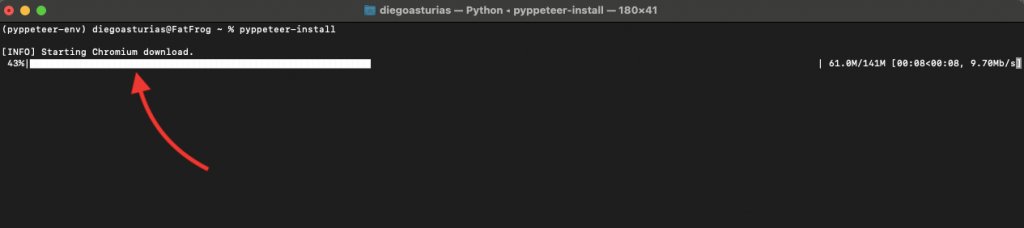
c. Configuring Pyppeteer with Chromium
When you run Pyppeteer for the first time, it will download the latest version of Chromium (if it is not already on your system). To avoid this from happening, ensure that a suitable Chrome/Chromium binary is installed. Then, run the “pyppeteer-install” command before using the library.
|
1 |
Pyppeteer-install |
d. Verifying the Installation
To verify that Pyppeteer is properly installed, you can run a simple script to open a web page and take a screenshot (for instance):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import asyncio from pyppeteer import launch async def take_screenshot(): print("Launching browser...") browser_instance = await launch() print("Opening new page...") new_page = await browser_instance.newPage() print("Navigating to example.org...") await new_page.goto('https://example.org') print("Taking screenshot...") await new_page.screenshot({'path': 'homepage.png'}) print("Closing browser...") await browser_instance.close() print("Screenshot saved as homepage.png") asyncio.run(take_screenshot()) |
What is and why you need ‘asyncio’? Asyncio is a Python module that provides infrastructure for writing single-threaded concurrent code. It uses the async/await syntax. The Asyncio module enables you to write code that can handle asynchronous I/O operations efficiently.
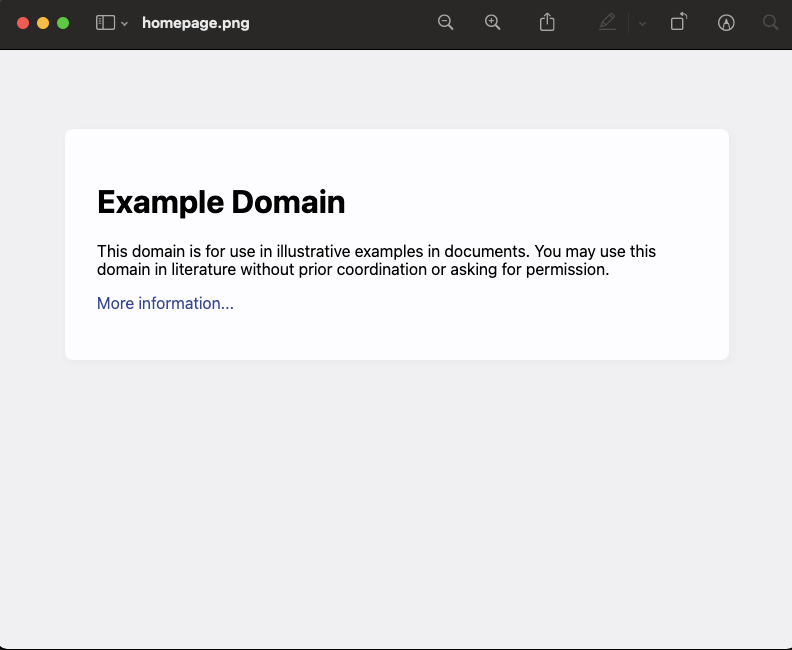
This script should save a screenshot of the example.com homepage as example.png
Now, let’s run the script in real life.
As you can see from the output (image below), the screenshot “homepage.png” was successfully taken and saved.
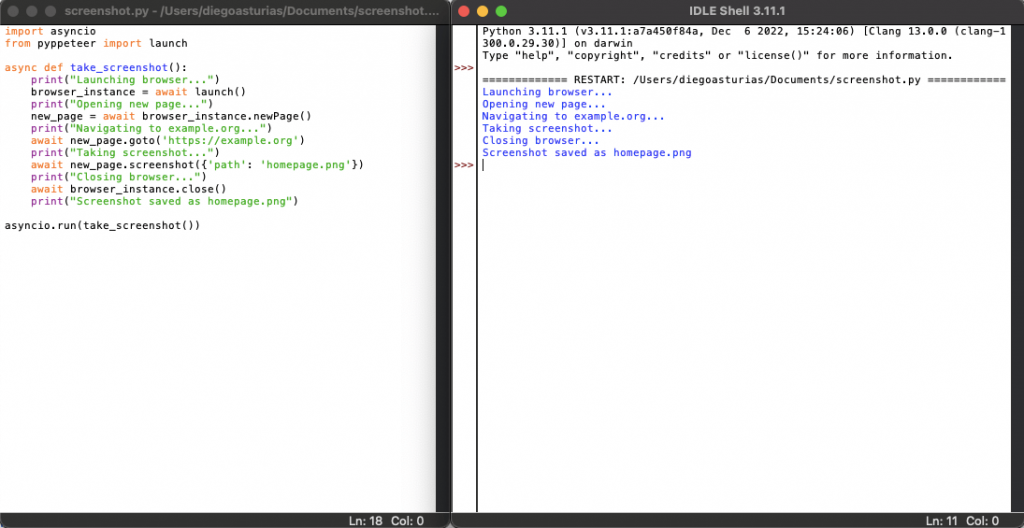
Note: The screenshot file homepage.png will be saved in the same directory where your script screenshot.py is located. This is because the screenshot method is instructed to save the file with the path ‘homepage.png’ (which is a relative path).
3. Basic Usage of Pyppeteer
In this section, we will go through four different examples of the basic usage of Pyppeteer. But before we move on, let’s briefly summarize Pyppeteer’s basic operations for simple tasks.
- Launching a Headless Browser: Use “launch()” to start a browser instance.
- Navigating to Web Pages: Open new pages with “newPage()” and navigate using “goto()”.
- Taking Screenshots: Capture screenshots with the “screenshot()” method.
- Extracting Page Content: Extract text and other content using the “evaluate()” method.
a. Launching a Headless Browser
If you don’t know yet, a headless browser is a web browser without a GUI. This type of browser allows for automated browsing tasks.
Here’s an example of how to launch a headless browser using Pyppeteer:
|
1 2 3 4 5 6 7 8 9 |
import asyncio from pyppeteer import launch async def launch_browser(): # Launching a headless browser browser_instance = await launch(headless=True) print("Browser launched" await browser_instance.close() print("Browser closed") asyncio.run(launch_browser()) |
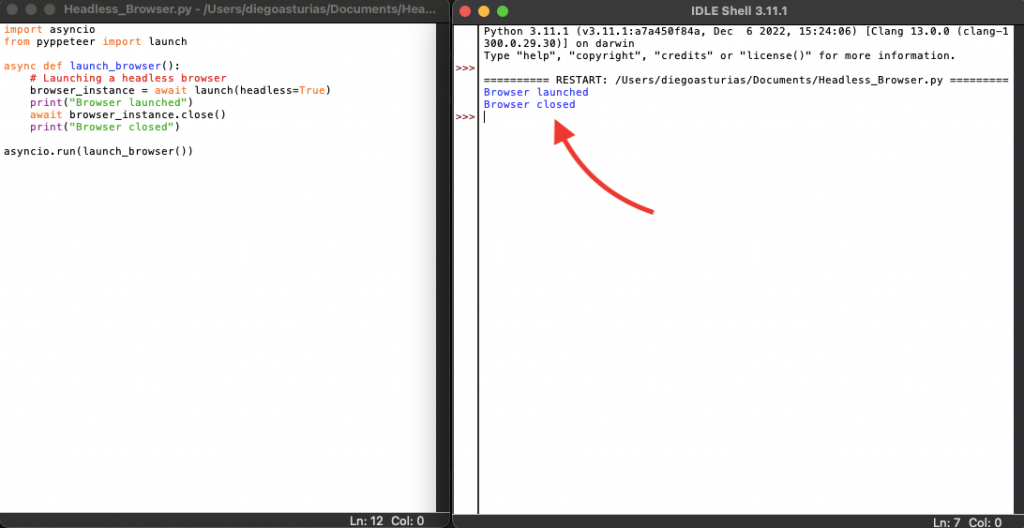
In this example, the launch() function starts a new headless browser instance. As you can see, we used the ‘headless=True’ parameter, which ensures that the browser runs without a GUI.
Now, let’s run the script in real life.
As you can see from the screenshot below, the headless browser launched and then closed.
b. Navigating to Web Pages
Once the browser is launched, you can navigate to a specific web page. Here’s how you can do that:
|
1 2 3 4 5 6 7 8 9 |
import asyncio from pyppeteer import launch async def navigate_page(): browser_instance = await launch(headless=True) new_page = await browser_instance.newPage() await new_page.goto('https://example.org') print("Navigated to https://example.org") await browser_instance.close() asyncio.run(navigate_page()) |
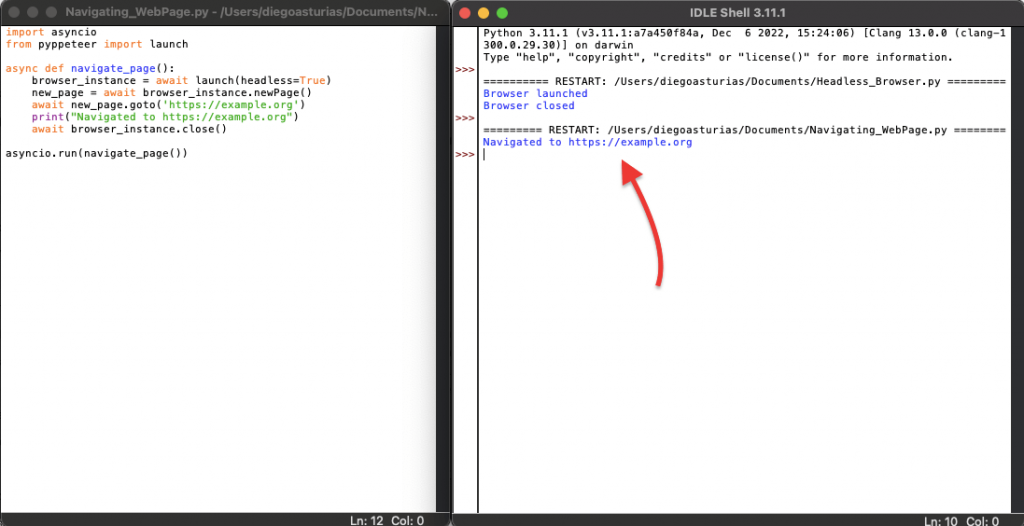
We used the newPage() method in the example script, which is used to open a new tab in the browser. In addition, we then used the goto() method to navigate to the specified URL.
Now, let’s run the script in real life.
As you can see from the screenshot below, the script successfully navigated the example web page.
c. Taking Screenshots
Pyppeteer is commonly used for taking screenshots of web pages (such as we did in our first example of testing Pyppeteer). Here’s an example of how to take a screenshot, with our script:
|
1 2 3 4 5 6 7 8 9 10 |
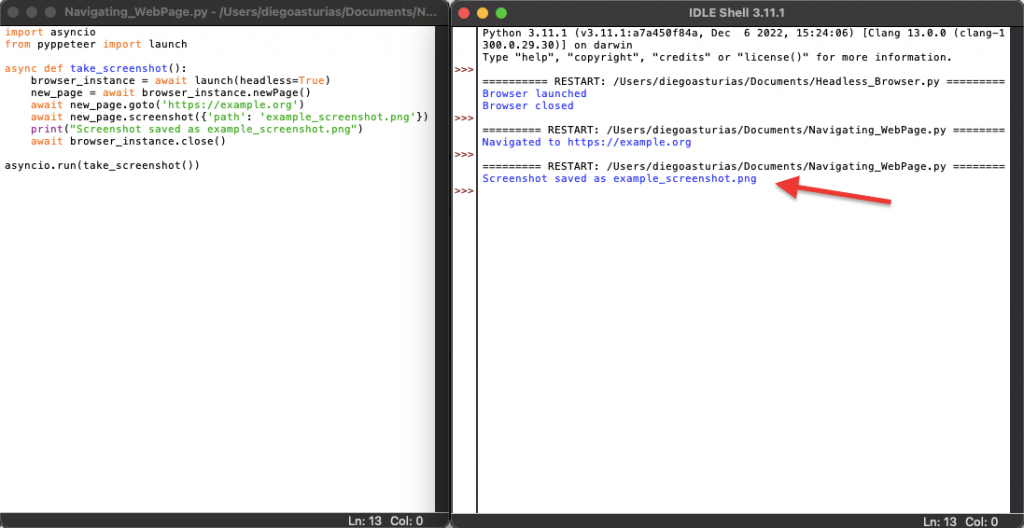
import asyncio from pyppeteer import launch async def take_screenshot(): browser_instance = await launch(headless=True) new_page = await browser_instance.newPage() await new_page.goto('https://example.org') await new_page.screenshot({'path': 'example_screenshot.png'}) print("Screenshot saved as example_screenshot.png") await browser_instance.close() asyncio.run(take_screenshot()) |
This script navigates to https://example.org and takes a screenshot, saving it as example_screenshot.png.
Now, let’s run the script in real life.
As you can see from the screenshot below, the script successfully took a screenshot from the example website.
d. Extracting Page Content
Extracting content from web pages is the most popular use of Pyppeteer. With it, you can evaluate JavaScript code in the page’s context and extract the desired content. Here’s an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
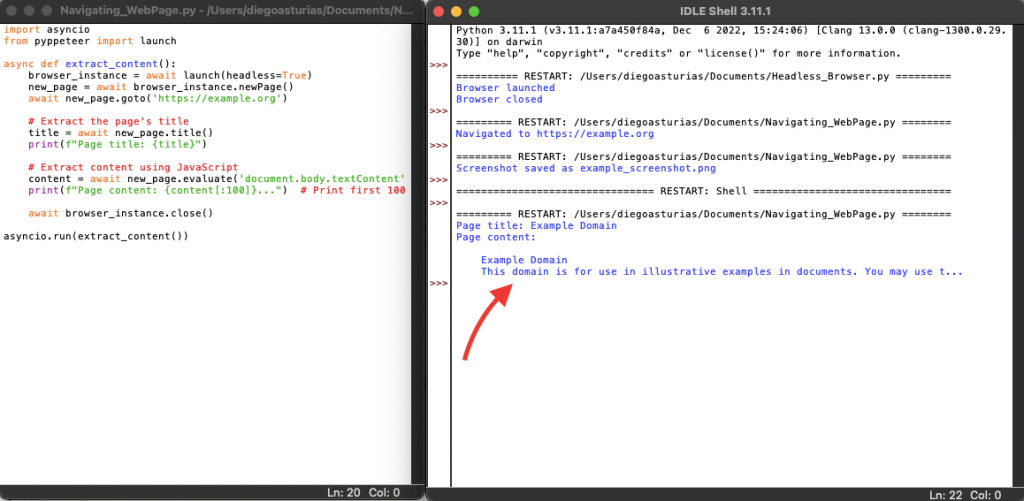
import asyncio from pyppeteer import launch async def extract_content(): browser_instance = await launch(headless=True) new_page = await browser_instance.newPage() await new_page.goto('https://example.org') # Extract the page's title title = await new_page.title() print(f"Page title: {title}") # Extract content using JavaScript content = await new_page.evaluate('document.body.textContent') print(f"Page content: {content[:100]}...") # Print first 100 characters of the content await browser_instance.close() asyncio.run(extract_content()) |
In this example, the title() method retrieves the page’s title. Then, the evaluate() method runs a JavaScript expression to get the text content of the body element.
Now, let’s run the script in real life.
As you can see from the last output, the script successfully extracted the page’s title, which is “Example Domain”. Additionally, it also extracted the content of the page body and printed the first 100 characters of it.
Ever hit a roadblock while scraping or automating tasks? ? Try Rapidseedbox.
Get reliable IPv4 and IPv6 proxies.
Experience low latency with high-end servers.
Stay anonymous with dedicated network bandwidth.
Always here for you with 24/7 Support.
————
4. Advanced Features of Pyppeteer.
In this section, we will go briefly through a couple of use cases and examples of how to use the advanced features of Pyppetter.
Skip this section, or go back to the previous one, if you are looking for simple tasks like launching a headless browser, navigating web pages, taking screenshots, or extracting page content.
But if you are looking for advanced functionalities and features of Pyppeteer, read on!
Here’s a summary of the advanced features:
These advanced features allow you to make the most out of Pyppeteer for complex web automation and scraping tasks.
- Web Scraping with Pyppeteer: Extract data from dynamic web pages using JavaScript evaluation.
- Working with Proxies: Use proxies to perform tasks anonymously and avoid getting blocked.
- Automating Browser Tasks: Automate sequences of browser actions like clicking buttons and navigating pages.
- Handling Forms and User Inputs: Interact with form elements and handle user inputs.
- Clicking and Evaluating Elements: Click on elements and evaluate JavaScript expressions to interact with the DOM.
- Evaluating JavaScript on Pages: Run JavaScript code on web pages to manipulate and retrieve data.
Example 1: Scrape Data from a Web Page
Here’s an example of how to scrape data from a web page. In this script, we navigate to https://example.org. We use the evaluate() method to run JavaScript in the context of the page to extract the inner text of the body element.
|
1 2 3 4 5 6 7 8 9 10 11 |
import asyncio from pyppeteer import launch async def scrape_data(): browser_instance = await launch(headless=True) new_page = await browser_instance.newPage() await new_page.goto('https://example.org') # Extract data from the page data = await new_page.evaluate('document.querySelector("body").innerText') print(f"Scraped data: {data[:100]}...") # Print the first 100 characters of the scraped data await browser_instance.close() asyncio.run(scrape_data()) |
Example 2: Working with Proxies
Here’s an example of how to use a proxy with Pyppeteer. In the following script, you’ll see the args parameter in the launch() method which specifies the proxy server to use. The rest of the script performs tasks as usual (but through the specified proxy server.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import asyncio from pyppeteer import launch async def use_proxy(): browser_instance = await launch( headless=True, args=['--proxy-server=http://your-proxy-server:port'] ) new_page = await browser_instance.newPage() await new_page.goto('https://example.com') # Perform tasks through the proxy content = await new_page.evaluate('document.body.textContent') print(f"Page content through proxy: {content[:100]}...") await browser_instance.close() asyncio.run(use_proxy()) |
Want to learn how to transfer data using URLs, with protocols like HTTP, FTP, and SFTP? Check our full guide to cURL (on Python).
5. Troubleshooting Common Issues
In this section, we will go through some debugging tips, handling browser errors, common errors and fixes.
In summary:
- For debugging, use logging, screenshots, console monitoring, and network tracking.
- Handle browser errors by adjusting timeouts, using try-except, and ensuring resource loading.
- Common issues include browser closures, element not found, slow loads, sessions, authentication and JavaScript failures.
Note: As a best practice and for reliable automation we recommend the following: modularize code, implement error handling, manage resources, use headless mode wisely, and update dependencies.
a. Debugging Tips
Debugging is a crucial part for any development process. Here are some tips to help you effectively debug your Pyppeteer scripts:
a.1 Verbose Logging:
Enable verbose logging to get detailed output from Pyppeteer. You can do this by setting the DEBUG environment variable:
|
1 |
export DEBUG="pyppeteer:*" |
This will print detailed logs of Pyppeteer’s internal operations to the console.
a.2 Use Screenshots:
We recommend you take screenshots at various steps in your script. This practice will help you confirm, visually the state of the page. It can help identify where things might be going wrong:
|
1 |
await page.screenshot({'path': 'debug_screenshot.png'}) |
a.3 Console Output:
Print the page’s console messages to the terminal to see errors or warnings from the web page itself:
|
1 |
page.on('console', lambda msg: print(f'Console message: {msg.text()}')) |
a.4 Network Activity:
Monitor network requests and responses to debug issues related to loading resources:
|
1 2 |
page.on('response', lambda response: print(f'Received response: {response.url}')) page.on('request', lambda request: print(f'Made request: {request.url}')) |
b. Handling Browser Errors
Browser errors can occur for various reasons. Here are some common browser errors and how to handle them:
b.1 Timeout Errors:
Adjust the default timeout settings if your scripts are running into timeout errors:
|
1 |
await page.goto('https://example.com', {'timeout': 60000}) # Set timeout to 60 seconds |
b.2 Navigation Failures:
Use the try-except block to catch and handle navigation errors:
|
1 2 3 4 |
try: await page.goto('https://example.com') except Exception as e: print(f"Navigation error: {e}") |
b.3 Resource Loading Issues:
Ensure all required resources are loaded before performing actions:
|
1 |
await page.waitForSelector('#elementID', {'timeout': 10000}) # Wait for element to load |
c. Common Errors and Fixes
Here are some common errors you might encounter and their solutions:
c.1 Browser Closed Unexpectedly:
Ensure your script waits for tasks to complete before closing the browser:
|
1 2 |
await page.waitForSelector('#elementID') await browser_instance.close() |
c.2 Element Not Found:
Double-check the selectors and ensure the element is available on the page:
|
1 2 3 |
element = await page.querySelector('#correctSelector') if not element: print("Element not found") |
c.3 JavaScript Evaluation Failures:
Ensure the JavaScript code being evaluated is correct. Plus ensure the necessary elements are present. Use the following:
|
1 |
content = await page.evaluate('document.body.textContent') |
c.4 Slow Page Load:
Increase the timeout or use ‘waitFor’ methods to ensure elements are fully loaded. For example:
|
1 2 |
await page.goto('https://example.com', {'timeout': 60000}) await page.waitForSelector('#elementID') |
C.5 Session Management:
Use incognito mode to avoid session-related issues:
|
1 2 |
context = await browser_instance.createIncognitoBrowserContext() page = await context.newPage() |
6. Pyppetee: FAQ
1. How does Pyppeteer relate to Puppeteer?
Puppeteer is a library developed for Node.js that provides a high-level API to control Chrome or Chromium browsers. Pyppeteer replicates the Puppeteer API in Python, enabling Python developers to perform similar browser automation tasks.
2. What programming language is Pyppeteer written in?
Pyppeteer is written in Python, making it accessible to Python developers who want to automate browser tasks without switching to a different programming language.
3. How do I install Pyppeteer?
You can install Pyppeteer using pip by running the following command: ‘pip install pyppeteer’ Alternatively, you can install the latest version from the GitHub repository: ‘pip install -U git+https://github.com/pyppeteer/pyppeteer@dev’
4. What is Chromium, and why is it required for Pyppeteer?
Chromium is an open-source web browser. It is the base for the popular Google Chrome. Pyppeteer uses Chromium to perform headless browser tasks.
5. How can I prevent Pyppeteer from downloading Chromium automatically?
To prevent Pyppeteer from downloading Chromium, you can ensure that a suitable Chrome or Chromium binary is already installed on your system.
6. How do I use Pyppeteer for web scraping?
Pyppeteer is the master for scraping data from web pages. You can do this by navigating to the page and evaluating JavaScript to extract the desired content. Use the examples provided throughout the article to learn how to scrape data with Pyppeteer.
7. What is headless mode in Pyppeteer?
Headless mode means, running a web browser without a GUI. It is useful for automated tasks because it reduces lots of resource usage. Plus, headless mode also allows the browser to run in environments without a display, such as servers.
8. How do I handle dynamic elements when web scraping with Pyppeteer?
To handle dynamic elements, you can use methods like waitForSelector to wait for elements to load before interacting with them. For example:
|
1 2 |
await page.waitForSelector('#dynamicElement') content = await page.evaluate('document.querySelector("#dynamicElement").innerText') |
9. What should I do if I encounter a Browser Closed Unexpectedly error?
Configure your script to wait for tasks to complete before closing the browser. For example, use waitFor methods to ensure all operations are finished:
|
1 2 |
await page.waitForSelector('#elementID') await browser.close() |
10. What are some useful libraries and tools to use alongside Pyppeteer?
Examples of useful libraries and tools (not limited to) to use with Pyppeteer include:
- BeautifulSoup: For parsing HTML and extracting data.
- pandas: For data manipulation and analysis.
- requests: For making HTTP requests.
- selenium: An alternative browser automation tool.
- Playwright: Another browser automation library that can be used as an alternative to Pyppeteer.
7. Final Words.
That is it folks, we hope you adopt this powerful toolkit, Pyppeteer for your new web scraping and browser automation projects. If you are a Python developer, this tool is a must!
What did we cover in this guide? From installation and setup to advanced web scraping and handling browser interactions, this guide covered all essential aspects of Pyppeteer.
Plus, we also went through the differences between Puppeteer and Pyppeteer (which is quite important if you come from JavaScript-based Puppeteer).
And last; In the troubleshooting section, we addressed common issues and offered solutions to improve the reliability of your script.
0Comments