With more than 666 million active users the former Twitter, or newly branded X, is one of the most popular social media platforms and a valuable source of information for businesses, researchers, and individuals. However, extracting and filtering data manually among the vast domain of Twitter data is overwhelming and non-functional.

Twitter scraping involves using software or scripts to collect data from the platform. You can analyze this data to gain invaluable insights into trending topics and hashtags, conversations, interactions happening on the platform, and user behavior.
The collected information can be meticulously analyzed for various purposes, such as sentiment analysis, market research, and social media monitoring. This article will plunge into different aspects of scraping Twitter data using existing methods, from scripting to no-code software, associated costs, and legality and ethical terms.
Table of Content
What Types of Data Can Be Extracted From Twitter?
You can extract different types of Twitter data. Here are three main datatypes for Twitter scraping:
- Tweets: You can capture specific data from filtered tweets based on profiles, such as their likes, replies, retweets, and specified URLs.
- User Profiles: Anything from a public user profile is collectible, such as the user’s bio, profile description, number of tweets, retweets, number of followers/ followings, and profile image.
- Keywords/Hashtags: You can collect tweets containing particular keywords, hashtags, or their combination. Refining your search by the number of likes or by looking up specific dates and times is also possible.
Legality and Ethical Terms of Use
When diving into the world of data scraping, it is essential to understand the legal and ethical boundaries involved.
According to the Twitter terms and regulations (Developer Agreement and Policy), scraping data without explicit permission is prohibited and declared by Twitter policy: “Scraping the Services without the prior consent of Twitter is expressly prohibited.
Any abuse of the Twitter API for these purposes will be subject to enforcement action, which may include suspension and termination of access.
General Guide for Scraping Twitter
After a brief introduction to Twitter scraping, it’s time to explore the process of scrapping through Twitter data. Thus, we’ve compiled a simple and comprehensive guide to Twitter scraping for you. Please follow the steps below:
- First, you need to have the right scraping tools. There are plenty of options to choose from. So, determine which option suits your budget and preferences.
- Download and install the scraping tool on your system.
- Make sure there is plenty of storage space available on your device and that you have a reliable internet connection.
- After installing, log in using your Twitter account details.
- Adjusting parameters for scraping data from Twitter is an important step that allows you to extract data based on keywords, hashtags, dates and times, locations, URLs, etc.
- After executing the scraper tool, a large amount of data will be left behind. You can export the data to different file formats (xlsx, CSV, JSON, etc.).
- In the final step, you should analyze the exported data to gain insights into your topic of interest.
Twitter Scraping Tools and Methods
We have reviewed some available scraping tools across the internet, from the official Twitter scraper to third-party services and even open-source Python libraries, and listed them below.
4.1. API-Based Twitter Scrapers
The first method that we are going to take a look at is API-based Twitter scrapers, which include Twitter API V2, Apify, Brightdata, and Scrapingdog.
4.1.1. Twitter API V2
Twitter API v2 is the latest version of Twitter`s API, the official and one of the most commonly used APIs for developers building apps with social interaction or researchers/individuals who collect data for their specific purpose. The use of new APIs enables the effortless monitoring and analysis of live conversations on social networks.
Recently, Twitter has added some new features, such as endpoints, payload options for tweet posts, conversation identifier sets, and annotations. These changes are quite impressive. However, the new pricing structure has made serious concerns for developers and third-party apps. With the new pricing structure, access to services has dramatically decreased, and prices have risen drastically.
The Twitter/X API v2 pricing plans have three levels: Free, basic, and enterprise.
- In the free tier, developers can post up to 1500 tweets per month, designed for write-only use and testing the Twitter API.
- The basic tier costs $100 per month and allows developers to post up to 3,000 tweets per month at the user level and 50,000 tweets (with a read limit of 10,000) at the app level.
- The Enterprise tire includes more advanced features designed for businesses. However, the enterprise plan will charge developers/businesses an exorbitant price of nearly 42000$ a month.
4.1.2. Apify
Through Apify’s Twitter Scraper, you can extract information from publicly available Twitter data such as hashtags, threads, replies, images, and more. Recent changes to Twitter have put new limits on viewing and scraping tweets on this platform, as users will only extract public information up to 100 tweets per profile. This scraper cannot scrape the latest tweets but can retrieve the most liked ones. Extracted data can be accessible in HTML, JSON, Excel, and CSV formats.
The following figure illustrates the monthly service costs by Apify. It also offers a 10% discount for the annual plan. For more information, visit Apify pricing.
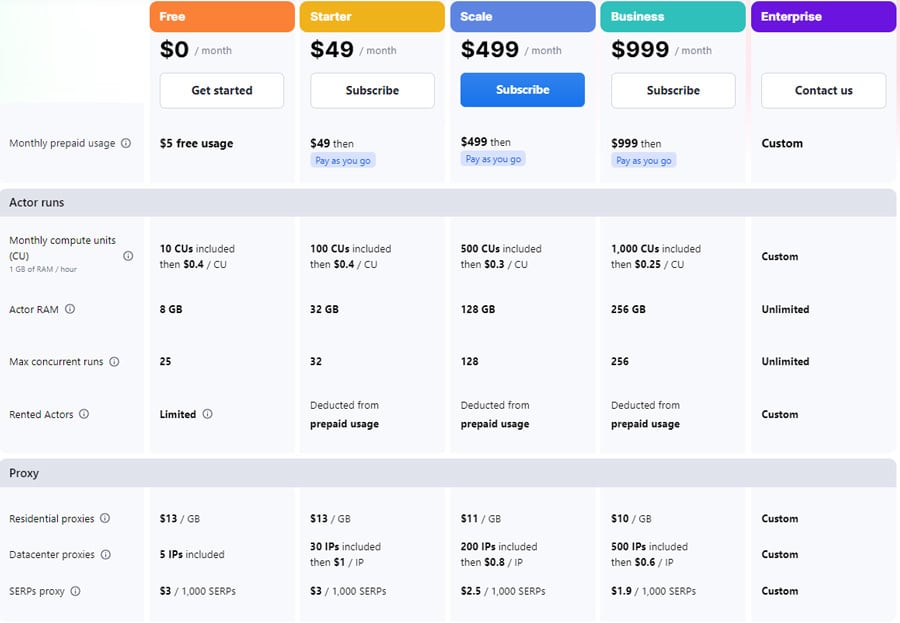
4.1.3. Brightdata
Bright Data is a data collection platform that offers web scraping tools such as proxy servers, APIs, and no-code solutions. Bright Data’s Web Scraper gives users the ability to extract data from public Twitter profiles, including images, videos, tweets, hashtags, and more.
Prices begin with a monthly 500$ for 151000 page loads. Bright Data Twitter scraper data collector is compatible with all web services and outputs its data in Excel format. It also offers a 7-day trial, and you can test the platform before paying 500 bucks.
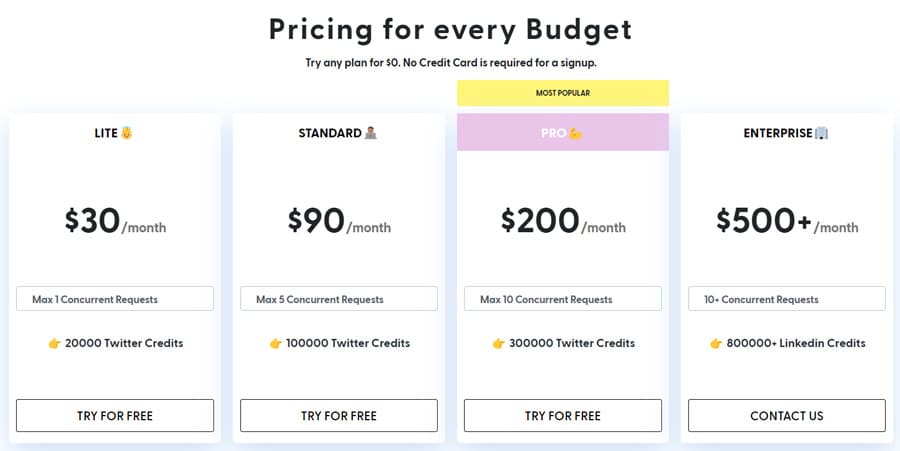
4.1.4. Scrapingdog
Scrapingdog is a web scraping API that helps you scrape any website, including Twitter. It allows you to scrape tweets using tweet IDs or scrape public pages to extract details such as number of followers, number of followers, and website links.
It costs you 0.0009$ per page to scrape Twitter in the standard plan, which is among the best value over price compared to the other top Twitter scrapers. They have also provided a free trial; you can cancel your subscription anytime and refund your money easily. For more information about how to scrape data using Scrapingdog, you can visit Twitter Scraping API documentation.
4.2. Python Libraries and Packages for Scraping Twitter
Now that you are familiar with the Twitter API and apps like Apify, it is time to take a look at the Python libraries and packages for Twitter scraping.
4.2.1. Tweepy
Tweepy is an open-source Python package that allows developers to access Twitter endpoints smoothly and transparently. However, you should be aware that Twitter has imposed limitations on the number of requests sent to the X/Twitter API, where 900 requests are allowed every 15 minutes. In this section, we aim to take a look at Tweepy’s functionality and give a simple example.
To begin, install the Tweepy package using the “pip install Tweepy” command on your Python IDE and then import Tweepy as well. Registering your client application with Twitter is the next step. Create a new application. Once completed, you will receive a bearer token.
Next, you must create a “Client” instance to pass the consumer bearer token you have gotten from the Twitter API.
In the query variable, we specified a field, a mention, and a hashtag as demonstrated.
To search for tweets from the past seven days, you can use the search_recent_tweets feature available in Tweepy. To specify the data you’re looking for, you need to pass a search query.
If you have access to the academic research product track, you can retrieve tweets older than 7 days. From the complete archive of publicly available tweets.
You can export the results using the following code.
There are also plenty of functions in Tweepy capable of performing various tasks in more complex and specific cases.
4.2.2. Snscrape
Another way to get information from Twitter without relying on an API is through Snscrape. It allows you to retrieve basic information like user profiles, tweet content, sources, etc. Unlike Tweepy, there are no limits on the number of tweets you can scrape or the dates of tweets, and you can extract old Twitter data. Since Snscrape is not connected to the Twitter API, it lacks functionality at the level of Tweepy. Check our complete guide to Snscrape.
In this section, we also review a basic example of scraping some data from Twitter using Snscrape in Python.
First, you should install Snscrape. Note that you must have Python 3.8 or higher installed to make it work.
In the next step, install the following libraries.
We send a query (in our case, “query”) using the “TwitterSearchScraper(query).get_items” function and obtain elements from the search just like the results from the Twitter search bar.
There are other methods that can be used for scraping data from Twitter, such as: TwitterSearchScraper, TwitterUserScraper, TwitterProfileScraper, TwitterHashtagScraper, TwitterTweetScraperMode, TwitterTweetScraper, TwitterListPostsScraper, TwitterTrendsScraper.
Conclusion
Twitter is a worthwhile source of sociological information across the web. By leveraging the information scraped from Twitter, you can tailor your plans to boost your sales and improve your marketing strategies. In this article, we have presented an in-depth overview of different aspects and methods of Twitter scraping for extracting data that can be valuable to businesses or research.
To sum up, according to the new limitations imposed on Twitter API v2 along with high costs, selecting the best scraper would be challenging. You can benefit from more advanced features on the Twitter API or third-party apps and Python libraries (Tweepy) that are directly connected to the Twitter API. But, the number of requests you can make is strictly limited. On the other hand, if you seek to scrape publicly available data and the basic features satisfy your needs, options like the Snscrape Python library can be a great choice.
Disclaimer: This material has been developed strictly for informational purposes. It does not constitute endorsement of any activities (including illegal activities), products or services. You are solely responsible for complying with the applicable laws, including intellectual property laws, when using our services or relying on any information herein. We do not accept any liability for damage arising from the use of our services or information contained herein in any manner whatsoever, except where explicitly required by law.
0Comments