En esta guía definitiva, exploraremos el mundo del web scraping, una potente técnica para extraer datos de sitios web.
Tanto si eres un principiante con curiosidad por el concepto como un programador experimentado que busca mejorar sus habilidades, esta guía tiene algo valioso para todos. Desde la comprensión de los fundamentos de la extracción de datos HTML utilizando selectores CSS y XPath hasta la práctica del web scraping con Python, tenemos todo cubierto. Además, abordaremos los aspectos legales, las consideraciones éticas y las mejores prácticas para garantizar un scraping web responsable.

Descargo de responsabilidad: Este material ha sido desarrollado estrictamente con fines informativos. No constituye respaldo de ninguna actividad (incluidas las actividades ilegales), productos o servicios. Usted es el único responsable de cumplir con las leyes aplicables, incluidas las leyes de propiedad intelectual, cuando utilice nuestros servicios o confíe en cualquier información contenida en este documento. No aceptamos ninguna responsabilidad por los daños que surjan del uso de nuestros servicios o la información contenida en este documento de ninguna manera, excepto cuando lo exija explícitamente la ley.
Tabla de contenidos.
- ¿Qué es el Web Scraping y cómo funciona?
- Fundamentos de la extracción de datos HTML: Selectores CSS y XPath.
- Web Scraping con Python (+ Código).
- ¿Es legal el web scraping?
- ¿Cómo intentan los sitios web bloquear el web scraping?
- Prácticas éticas y recomendadas para el Web Scraping.
- Web Scraping: Preguntas más frecuentes (FAQ)
- Palabras Finales.
1. ¿Qué es el Web Scraping y cómo funciona?
El web scraping (también conocido como web harvesting o extracción de datos) es el proceso de extracción automática de datos de sitios web, servicios web y aplicaciones web.
El raspado web nos evita tener que entrar en cada sitio web y extraer los datos manualmente, un proceso largo e ineficaz. El proceso consiste en utilizar scripts o programas automatizados. El script o programa accede a la estructura HTML de la página web, analiza los datos y extrae los elementos específicos necesarios de la página para su posterior análisis.
a. ¿Para qué se utiliza el Web Scraping?
El web scraping es fantástico si se hace con responsabilidad. En general, puede utilizarse para investigar mercados, por ejemplo para obtener información y conocer las tendencias de un mercado concreto. También es popular en el seguimiento de la competencia para conocer su estrategia, precios, etc.
Los casos de uso más específicos son:
- Plataformas sociales (Raspado de Facebook y Twitter)
- Control en línea de los cambios de precios,
- Revisiones de productos,
- Campañas SEO,
- Listados inmobiliarios,
- Seguimiento de los datos meteorológicos,
- Seguimiento de la reputación de un sitio web,
- Seguimiento de la disponibilidad y los precios de los vuelos,
- Pruebe los anuncios, independientemente de la geografía,
- Control de los recursos financieros,
b. ¿Cómo funciona el Web Scraping?
Los elementos típicos que intervienen en el web scraping son el iniciador y el objetivo. El iniciador (web scraper) utiliza software de extracción automática de datos para raspar sitios web. Los objetivos, por su parte, suelen ser el contenido del sitio web, información de contacto, formularios o cualquier cosa disponible públicamente en la web.
El proceso típico es el siguiente:
- PASO 1: El iniciador utiliza la herramienta de scraping: un software (que puede ser un servicio basado en la nube o un script casero) para empezar a generar peticiones HTTP (utilizadas para interactuar con sitios web y recuperar datos). Este software puede iniciar cualquier cosa, desde una solicitud HTTP GET, POST, PUT, DELETE o HEAD, hasta una solicitud OPTIONS a un sitio web de destino.
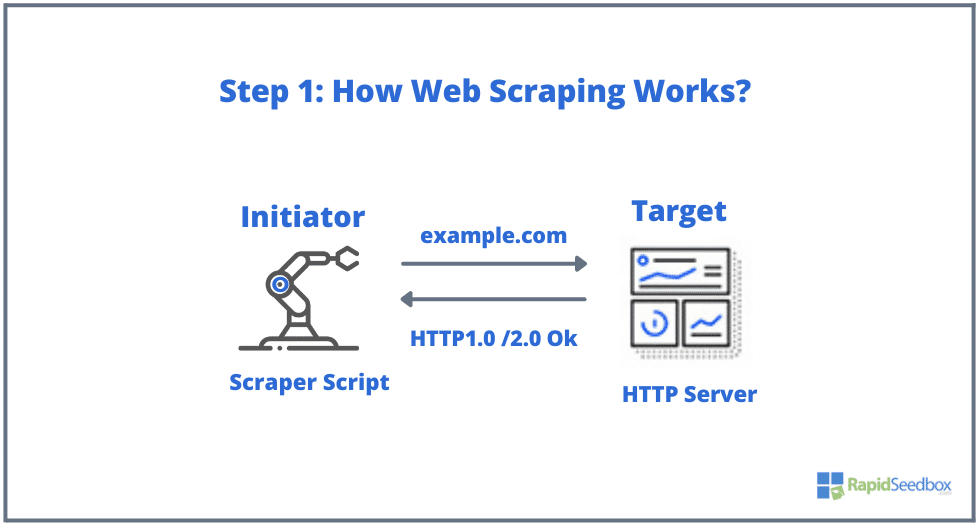
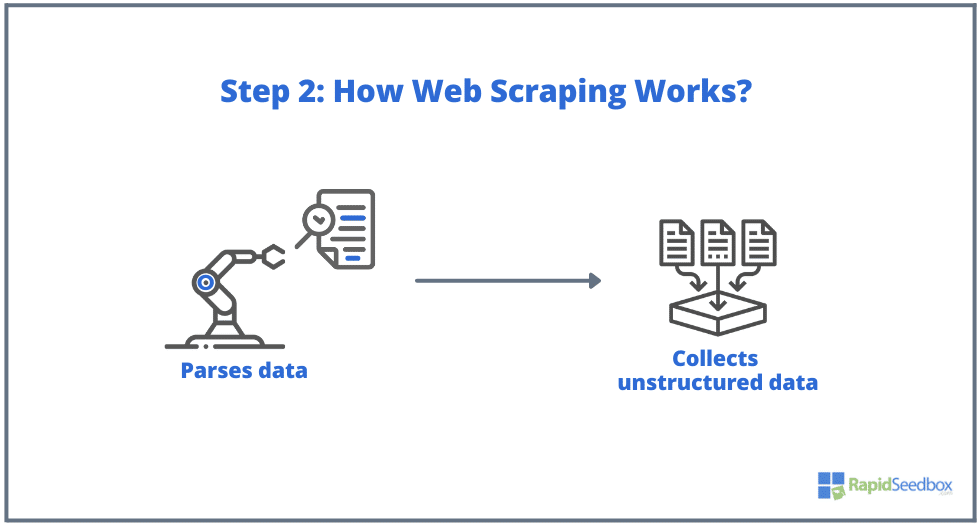
- PASO 2. Si la página existe, el sitio web de destino respondería a la solicitud del scraper con el HTTP/1.0 200 OK (la respuesta típica a los visitantes.) Cuando el scraper recibe la respuesta HTML (por ejemplo 200 OK), procedería a analizar el documento y recopilar sus datos no estructurados.
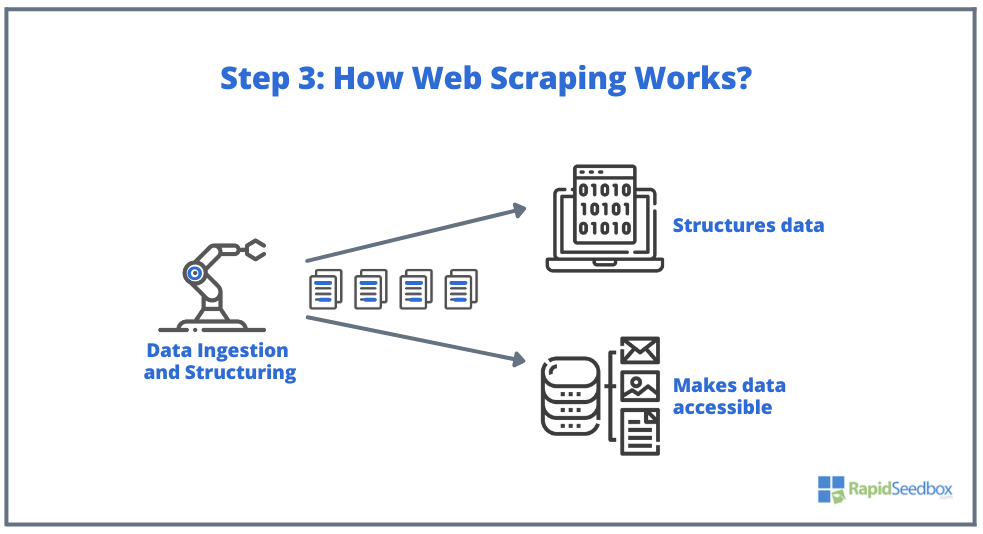
- PASO 3. A continuación, el software scraper extrae los datos en bruto, los almacena y añade estructura (índices) a los datos según lo especificado por el iniciador. Los datos estructurados son accesibles a través de formatos legibles como XLS, CSV, SQL o XML.
2. Fundamentos de la extracción de datos HTML: Selectores CSS y XPath.
Puede que ya conozcas lo básico: El web scraping consiste en extraer datos de sitios web, y todo comienza con HTML-.la columna vertebral de las páginas web. Dentro de un archivo HTML, encontrará clases e identificadores, tablas, listas, bloques o contenedores: todos ellos elementos básicos que conforman la estructura de una página.
CSS, por su parte, es un lenguaje de hojas de estilo utilizado para controlar la presentación y el diseño de los documentos HTML. Define cómo se muestran los elementos HTML en una página web, como colores, fuentes, márgenes y posicionamiento. CSS desempeña un papel clave en el web scraping, ya que ayuda a extraer datos de los elementos deseados.
Nota: Explicar en detalle qué es HTML y CSS y cómo funcionan, está fuera del alcance de este artículo. Asumimos que ya tienes los conocimientos fundamentales de HTML y CSS.
Aunque sería posible extraer datos directamente del HTML sin procesar utilizando diversas técnicas, como expresiones regulares, puede resultar realmente laborioso y complicado. Dado que el lenguaje estructurado de HTML se diseñó para ser "legible por máquinas", puede resultar muy complejo y variado. Aquí es donde los selectores CSS y XPath desempeñan un papel fundamental.
a. Compilación e inspección de HTML.
En la siguiente sección, proporcionaremos algunos ejemplos de selectores CSS y XPath (compilados e inspeccionados). Todos los siguientes ejemplos HTML y CSS han sido compilados con el editor en línea HTML-CSS-JS.
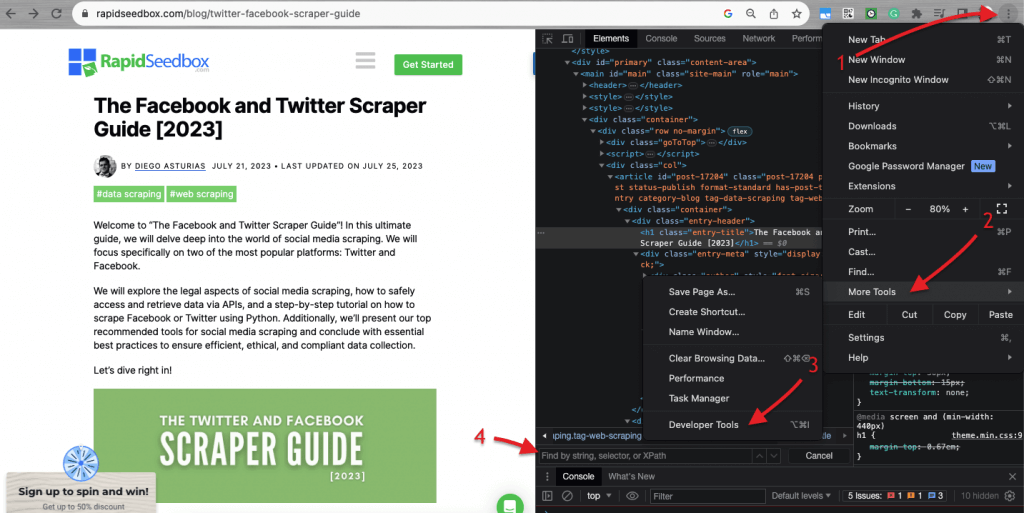
A la hora de inspeccionar el código HTML de los sitios web, Los navegadores web vienen con herramientas para desarrolladores, por lo que puedes inspeccionar literalmente el HTML o CSS que está disponible públicamente en cualquier página web. Puedes hacer clic con el botón derecho en una página web y seleccionar "Inspeccionar", "Inspeccionar elemento" o "Inspeccionar fuente". Para comparar mejor la página y la dinámica del código, en el navegador Chrome > ve a los tres puntos de la parte superior izquierda (1) > Más herramientas (2) > Herramientas para desarrolladores (3).
Las herramientas para desarrolladores incluyen un práctico filtro de búsqueda (4) que permite buscar por cadena, selector o XPath. Como ejemplo, vamos a raspar algunos datos de: https://www.seedhost.net/wp/blog/twitter-facebook-scraper-guide.
b. Selectores CSS:
Los selectores CSS son patrones utilizados para seleccionar y orientar los elementos HTML de una página web. Son útiles para el web scraping (y el styling), ya que proporcionan una forma más eficiente y específica de obtener datos de documentos HTML. Aunque es posible extraer datos directamente del HTML sin procesar utilizando varias técnicas como expresiones regulares, los selectores CSS ofrecen varias ventajas que los convierten en la opción preferida para el web scraping.
Técnicas de orientación y selección de elementos HTML dentro de una página web:
i. Selección de nodos.
La selección de nodos es el proceso de elegir elementos HTML basándose en sus nombres de nodo. Por ejemplo, seleccionar todos los elementos 'p' o todos los elementos 'a ' de una página. Esta técnica permite seleccionar tipos específicos de elementos en el documento HTML.

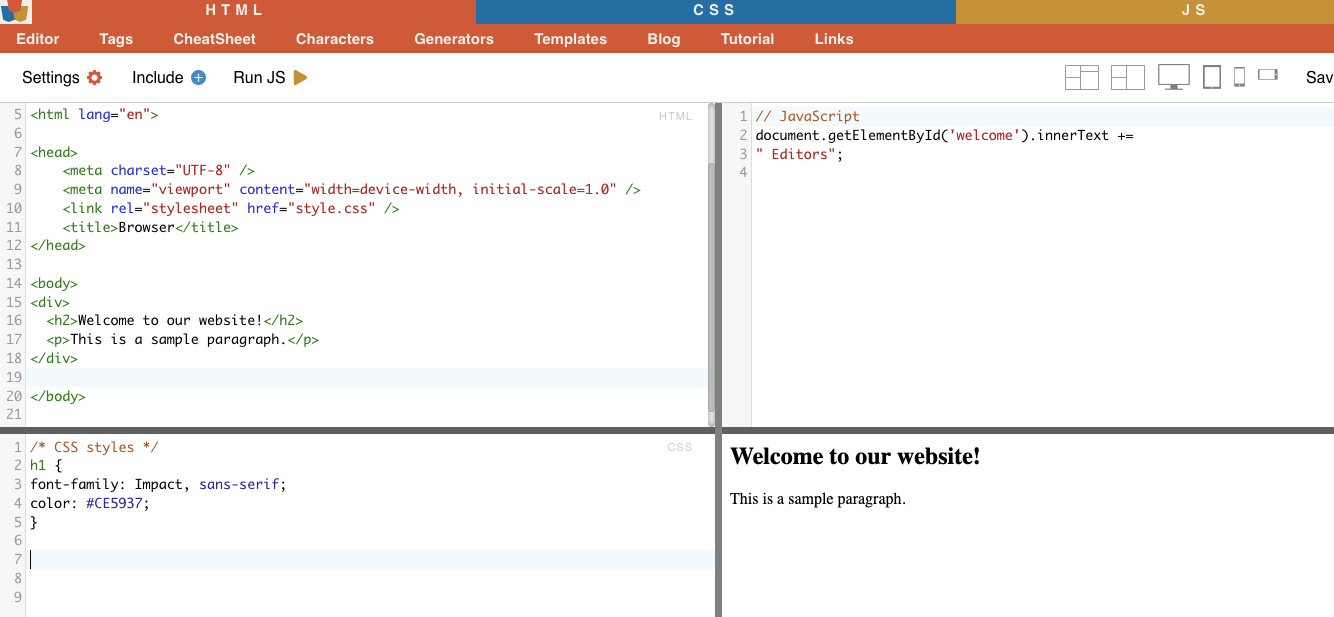
Ejemplo de la vida real: Búsqueda manual de H2.
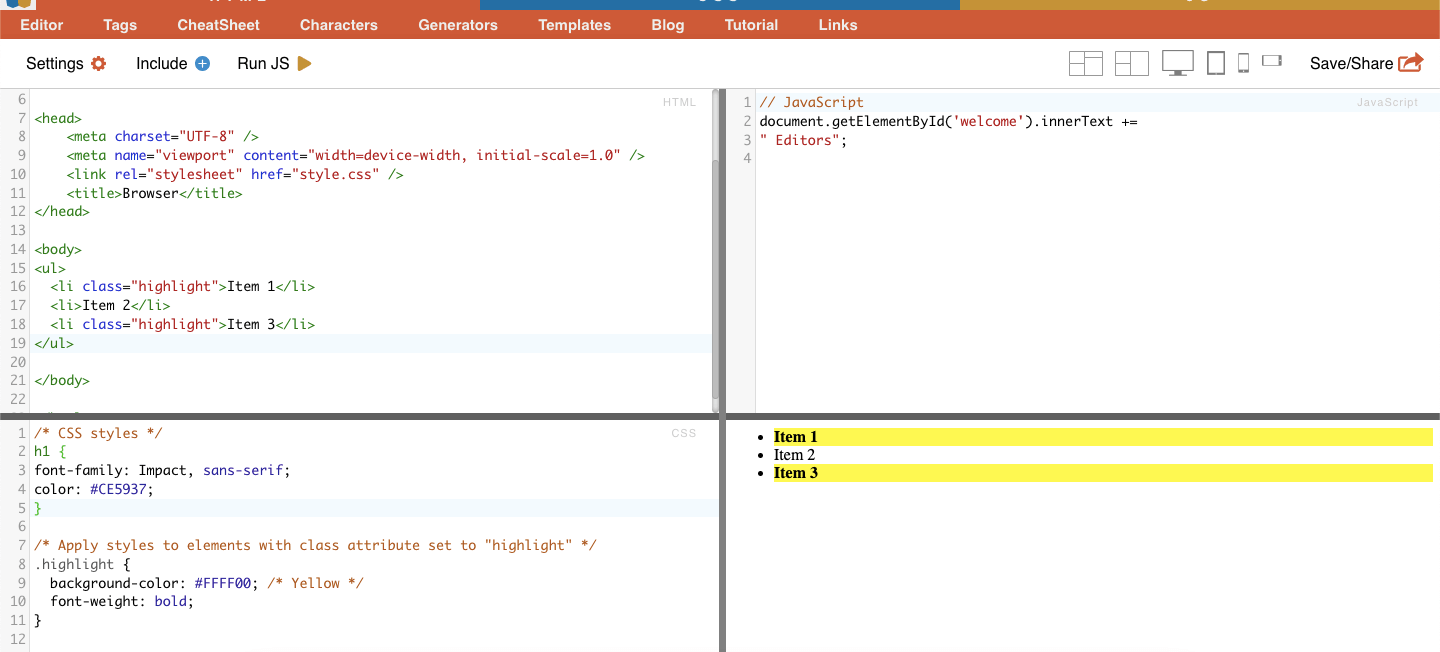
ii. Clase.
En los selectores CSS, la selección de clase consiste en seleccionar elementos HTML en función del atributo de clase que tengan asignado. El atributo class permite aplicar un nombre de clase específico a uno o más elementos. Además en los estilos CSS o JavaScript, se puede aplicar a todos los elementos con esa clase. Ejemplos de nombres de "clase" son botones, elementos de formulario, menús de navegación, diseños de cuadrícula, etc.
Por ejemplo: El siguiente selector CSS: 'highlight' seleccionará todos los elementos cuyo atributo de clase sea "highlight".


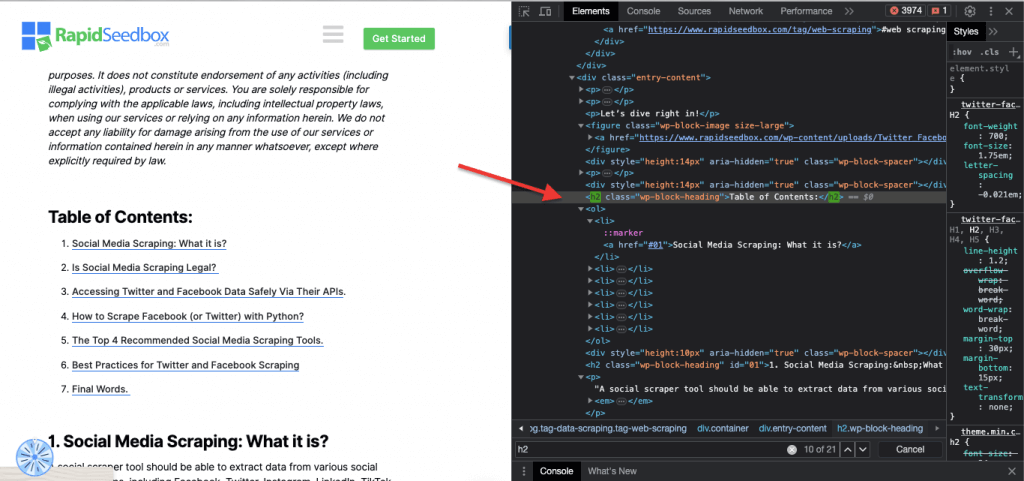
Ejemplo de la vida real: Búsqueda manual de clases.
iii. Restricciones de identificación.
Las restricciones ID ayudan a seleccionar un elemento HTML basándose en su atributo ID único. Este atributo ID se utiliza para identificar de forma única un único elemento en la página web. A diferencia de las clases, que pueden utilizarse en varios elementos, los ID deben ser únicos dentro de la página.
Por ejemplo: El selector CSS '#header' seleccionará el elemento cuyo atributo ID sea "header".


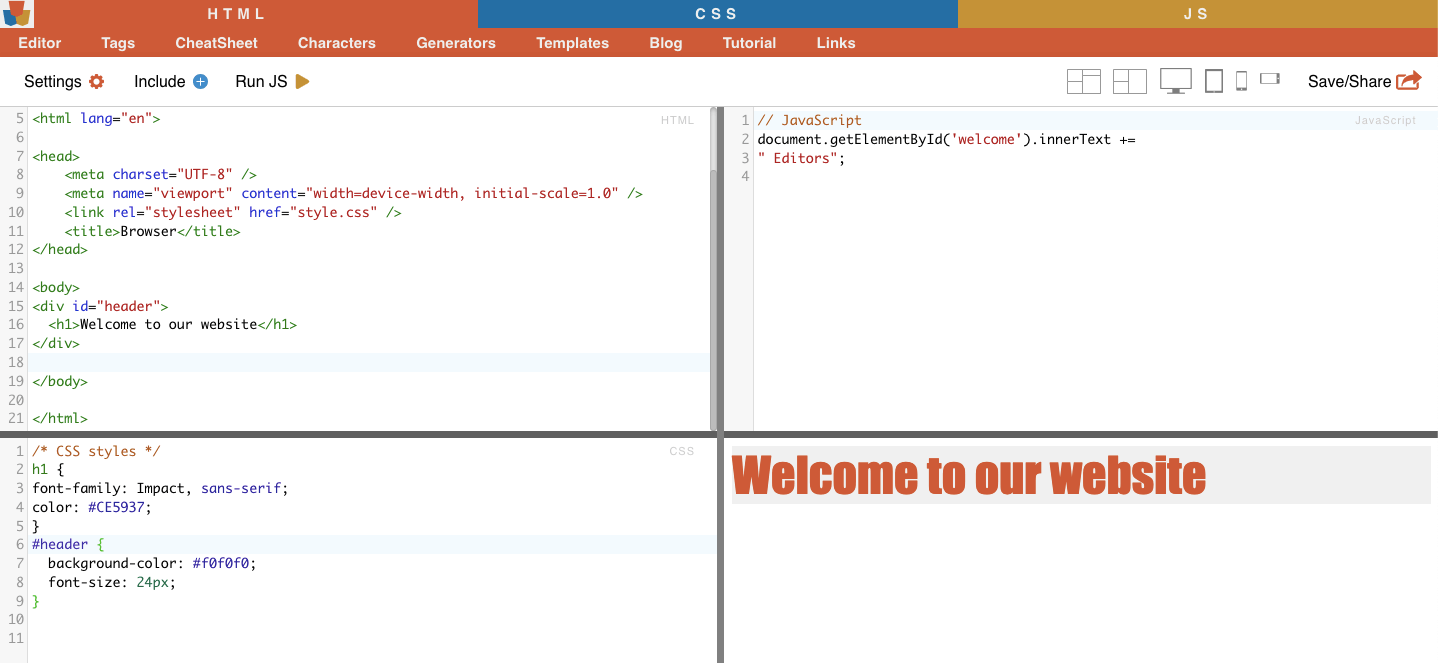
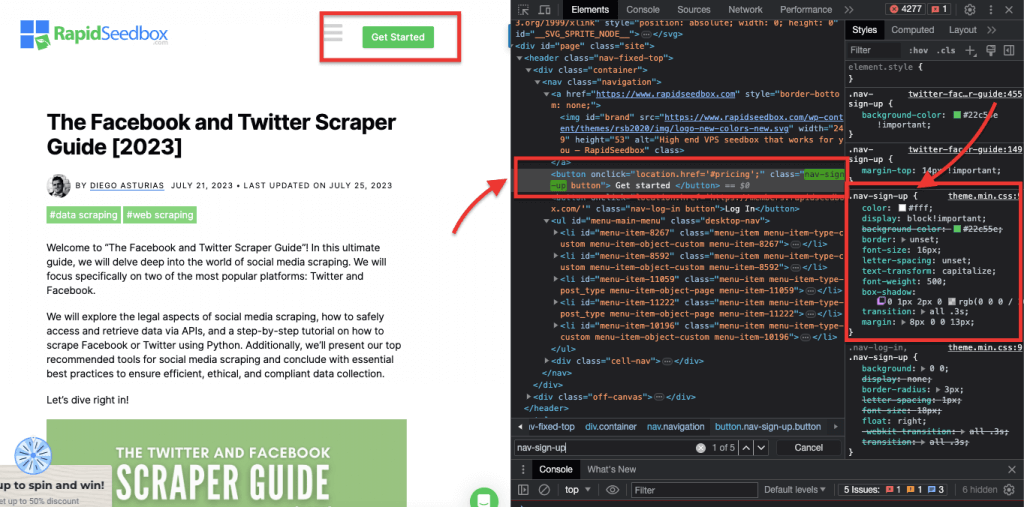
Ejemplo de la vida real: Buscar manualmente los identificadores. Después de encontrar el #01 tendrá que localizar el id="01″.
iv. Correspondencia de atributos.
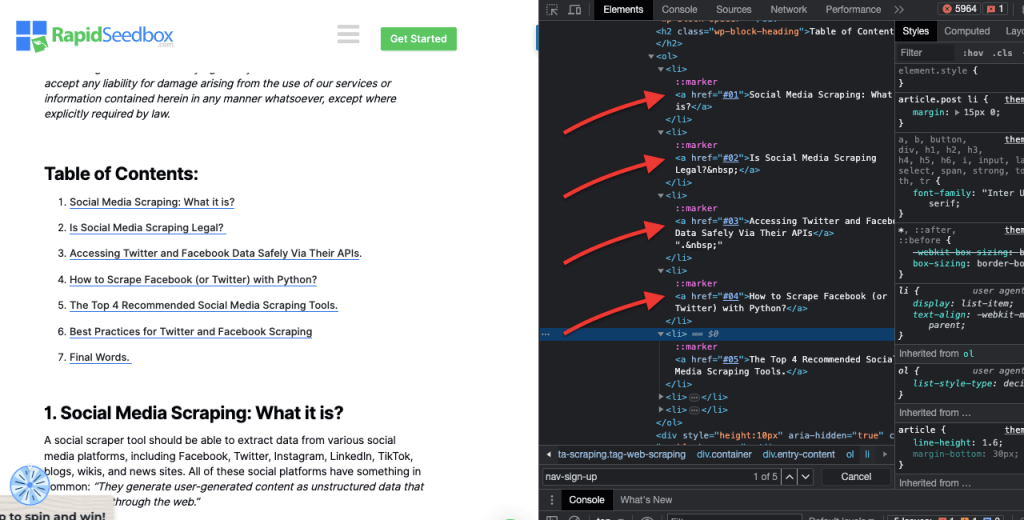
Esta técnica consiste en seleccionar elementos HTML basándose en atributos específicos y sus valores. Permite seleccionar elementos que tengan un atributo o valor de atributo concreto. Existen distintos tipos de concordancia de atributos, como la concordancia exacta, la concordancia de subcadenas, etc.
Por ejemplo: El siguiente ejemplo muestra un atributo personalizado llamado tipo de datos. Para seleccionar o aplicar estilo a determinados elementos (por ejemplo, elementos de lista marcados como "fruta") puede utilizar el selector CSS que selecciona elementos en función de los valores de sus atributos.
Para raspar sólo los elementos marcados como "fruta", puede utilizar el siguiente selector CSS:

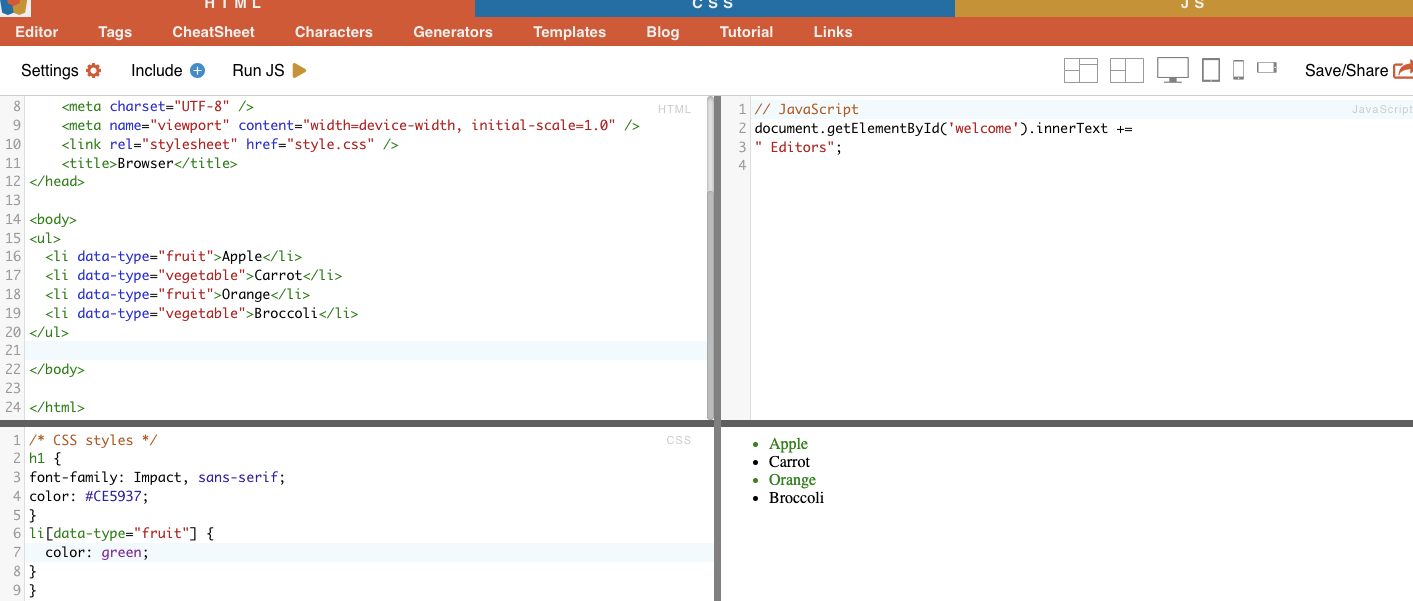
Ejemplo de la vida real: Búsqueda manual de atributos.
c. Selectores Xpath:
Los selectores CSS son ideales para tareas sencillas de web scraping en las que la estructura HTML es relativamente simple. Pero cuando la estructura HTML se vuelve más intrincada y compleja, existe otra solución: Los selectores XPath.
Selectores XPath (selectores del lenguaje de rutas XML) es un lenguaje de rutas flexible que se utiliza para navegar por los elementos de un documento XML o HTML. Ayudan a seleccionar nodos específicos dentro del código HTML basándose en su ubicación, nombres, atributos o contenido. Los selectores XPath también pueden ser útiles para seleccionar elementos basándose en sus atributos de clase e ID.
He aquí tres ejemplos de selectores XPath para web scraping.
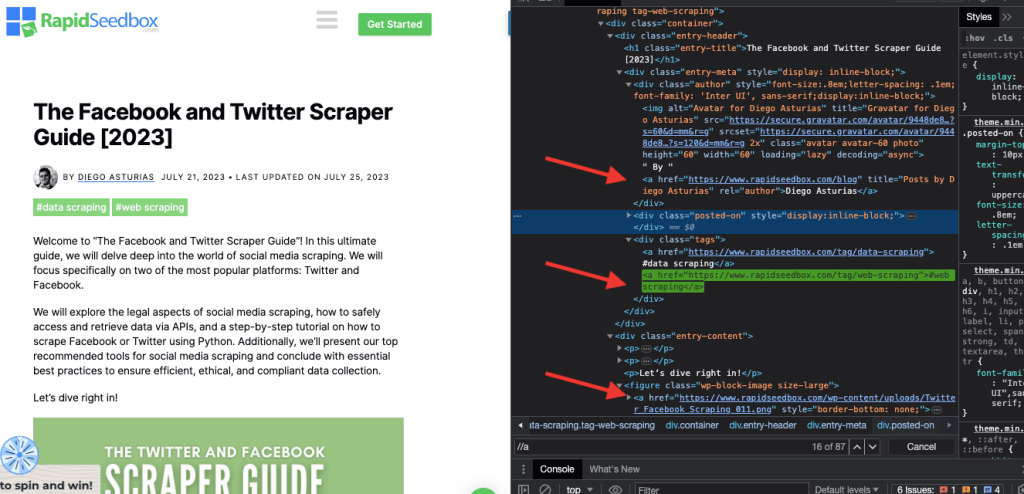
i. Ejemplo 1: Expresión XPath: ' //a
La expresión XPath ' //a' selecciona todos los elementos '' de la página, independientemente de su ubicación en el documento. La siguiente captura de pantalla muestra la localización manual de todos los elementos '' de la página.
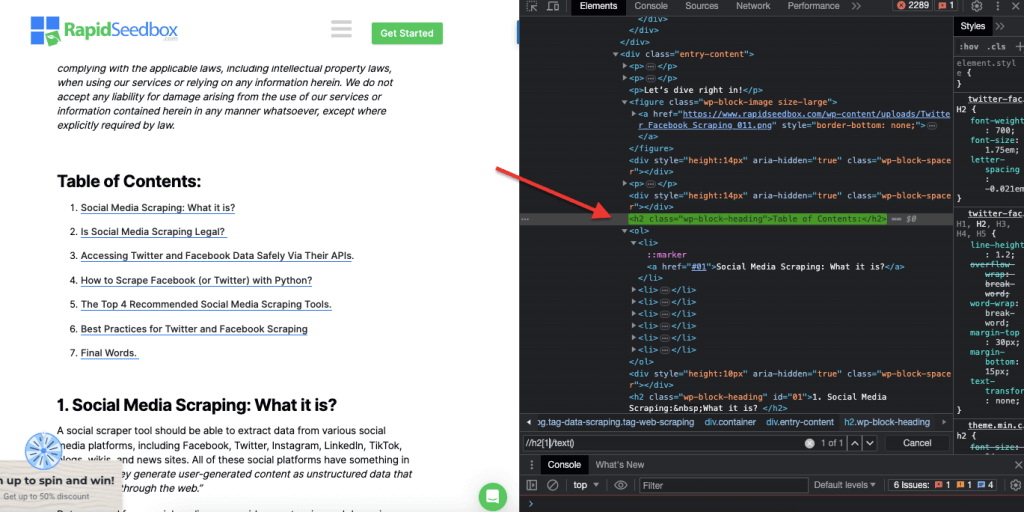
ii. Ejemplo 2: ' //h2[1]/text()'
La expresión XPath:
' //h2[1]/text() '
Seleccionará el contenido de texto del primer encabezado h2 de la página. El índice '[1]' se utiliza para especificar la primera aparición del elemento h2, también puede especificar la segunda aparición con el índice '[2]', y así sucesivamente. La siguiente captura de pantalla muestra la localización manual del primer encabezado h2 en la página utilizando este selector XPath.
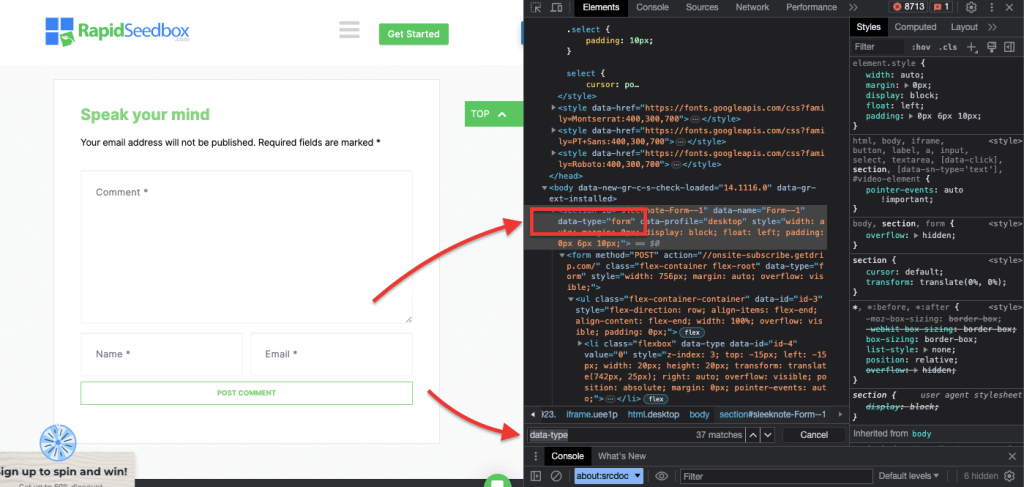
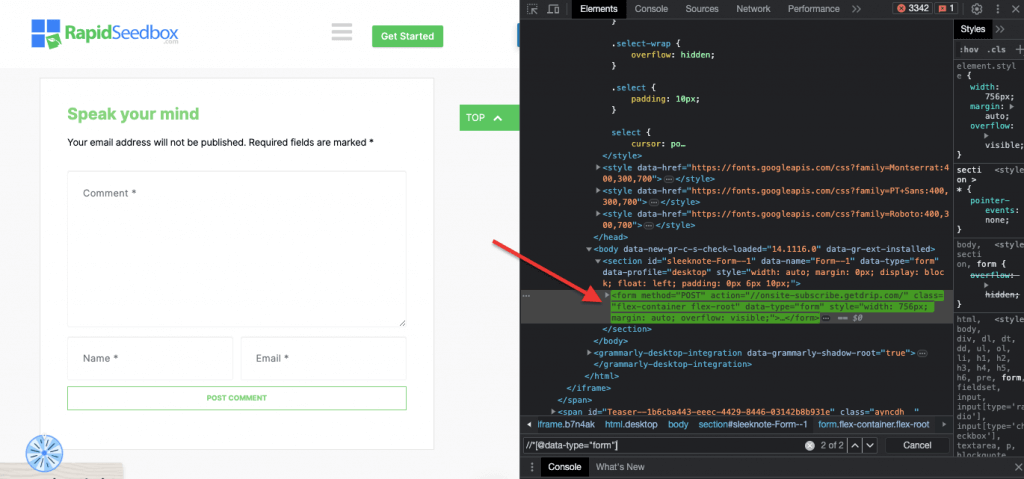
iii. Ejemplo 3. ' //* [@data-type="form"]'
La expresión XPath //* [@data-type="form"] selecciona todos los elementos que tienen un atributo data con el valor "form". La dirección * indica que se seleccionará cualquier elemento con el atributo de datos especificado, independientemente de su nombre de nodo. La siguiente captura de pantalla muestra el proceso para localizar manualmente los elementos con el valor "form".
Inspeccionar visualmente y extraer datos manualmente de una página HTML utilizando estos selectores CSS y XPath no sólo puede llevar mucho tiempo, sino que también es propenso a errores. Además, la extracción manual o visual de datos es totalmente inadecuada para la recopilación de datos a gran escala o para tareas de scraping repetitivas. Aquí es donde el scripting y la programación son altamente beneficiosos.
¿Busca proxies fiables para el web scraping?
Aumente la eficacia de su raspado web con los servicios proxy de alta calidad de RapidSeedbox. Disfrute de un scraping rápido, seguro y anónimo.
¿Cuáles son los mejores lenguajes de programación para el web scraping?
El lenguaje de programación más popular para scraping es Python debido a sus librerías y paquetes (más sobre esto en la siguiente sección.) Otro lenguaje de programación popular para web scraping es Rya que también cuenta con un fantástico conjunto de bibliotecas y frameworks compatibles. Además, también merece la pena mencionar C#, un lenguaje de programación popular que utilizan muchos raspadores web. Sitios web como ZenRows tienen guías completas sobre cómo scrapear un sitio web en C#que facilita a los desarrolladores la comprensión del proceso y la puesta en marcha de sus propios proyectos.
En aras de la simplicidad, esta guía de web scraping se centrará en el web scraping con Python. Siga leyendo.
3. Web Scraping con Python (con código).
¿Por qué inspeccionar visualmente y extraer manualmente datos HTML mediante selectores CSS o selectores XPath cuando puedes utilizarlos de forma sistemática y automática con lenguajes de programación?
Existen muchas bibliotecas y marcos de trabajo populares para el web scraping que admiten selectores CSS para facilitar la extracción de datos. Uno de los lenguajes de programación más populares para el web scraping es Pythonpara sus bibliotecas como BeautifulSoup, Solicitudes, CSS-Select, Selenio, y Chatarra. Estas bibliotecas permiten a los raspadores web aprovechar los selectores CSS y XPath para extraer datos de forma eficaz.
BeautifulSoup.
BeautifulSoup es uno de los paquetes Python más populares y potentes diseñados para analizar documentos HTML y XML. Este paquete crea un árbol de análisis sintáctico de las páginas, lo que le permite extraer fácilmente datos de HTML.
| Dato Interesante! En la lucha contra COVID-19, DXY-COVID-19-Crawler de Jiabao Lin utilizó BeautifulSoup para extraer datos valiosos de un sitio web médico chino. De este modo, ayudó a los investigadores a controlar y comprender la propagación del virus. [Fuente: Elevador lateral] |
Peticiones.
Python Solicitudes es una sencilla pero potente librería HTTP. Es útil para hacer peticiones HTTP para recuperar datos de sitios web. "Requests" simplifica el proceso de envío de peticiones HTTP y el manejo de las respuestas en tu proyecto Python de web scraping.
a. Tutorial para Web Scraping con Python (+ Código)
En este tutorial de web scraping con Python, obtendremos datos de un sitio web HTML de destino utilizando código Python con los "requests" y la librería BeautifulSoup.
Requisitos previos:
Asegúrese de que se cumplen los siguientes requisitos previos:
- Entorno Python: Asegúrese de tener Python instalado en su ordenador. Además, asegúrese de que puede ejecutar el script en su entorno Python preferido (por ejemplo, IDLE or Cuaderno Jupyter).
- Biblioteca de solicitudes: Instale el
solicitabiblioteca. Se utiliza para enviar peticiones HTTP GET a la URL especificada. Puede instalarla utilizandopipcorriendopip install solicitudesen el símbolo del sistema o en el terminal. - Biblioteca BeautifulSoup: Instale el
beautifulsoup4biblioteca. Puede instalarla utilizandopipcorriendopip install beautifulsoup4en tu terminal.
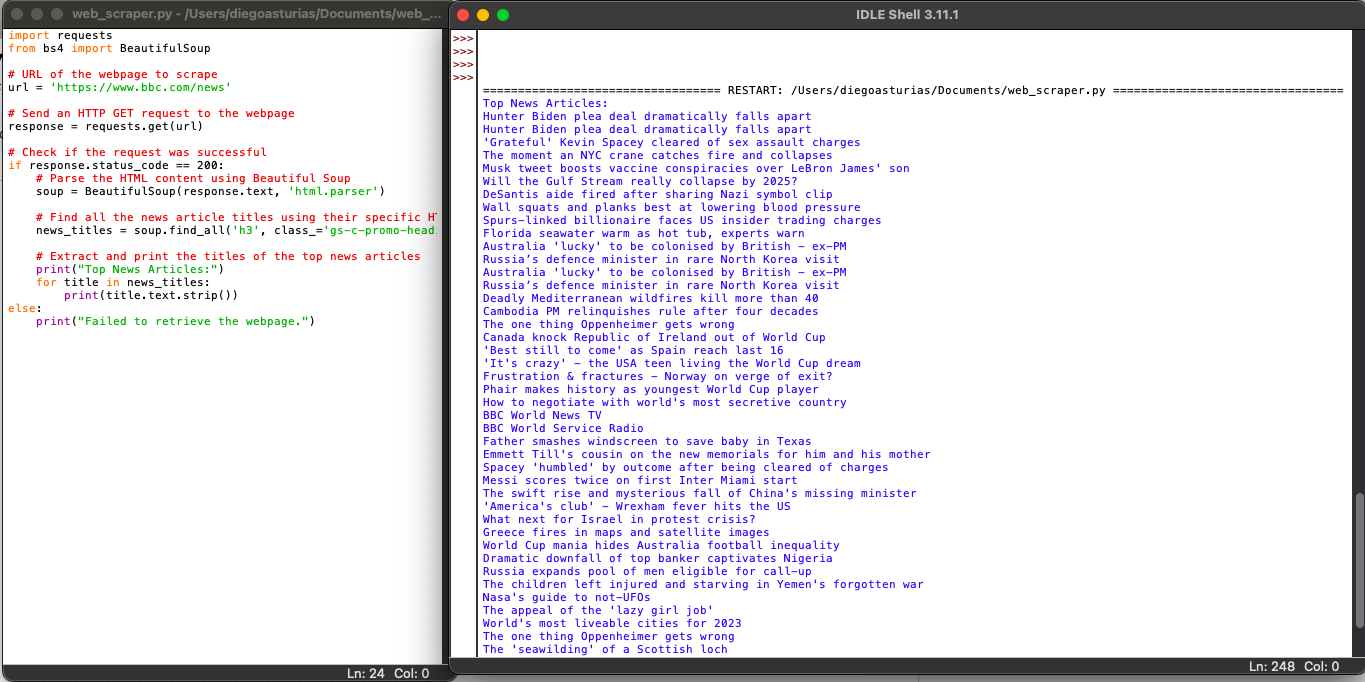
El código Python para el web scraping de datos de una página (con BeautifulSoup)
El siguiente script obtendrá la URL especificada, analizará el contenido HTML utilizando BeautifulSoup e imprimirá los títulos de los principales artículos de noticias de la página web.

Cuando se ejecuta el script en IDLE Shell, la pantalla imprime todos los "news_titles" recopilados del sitio web objetivo.
b. Variaciones de nuestro código Python para el web scraping.
Podemos tomar nuestro anterior código Python de raspado web y hacer algunas variaciones para raspar diferentes tipos de datos.
Por ejemplo:
- Encontrar imágenes: Para encontrar todas las etiquetas de imagen (
) en la página web, puede utilizar el método find_all() con el nombre de etiqueta 'img':

- Encontrar enlaces: Para encontrar todas las etiquetas de anclaje () que representan enlaces en la página web, puede utilizar el método find_all() con el nombre de etiqueta 'a':

El script proporcionado (junto con variaciones) es un script básico de web scraping. Simplemente extrae e imprime los títulos de los principales artículos de noticias de la URL especificada. Pero, por desgracia, este sencillo script carece de muchas características que conforman un proyecto de web scraping más completo. Hay varios elementos que podría considerar añadir: almacenamiento de datos, gestión de errores, paginación/rastreo, uso de agentes de usuario y cabeceras, medidas de estrangulamiento y cortesía, y capacidad para gestionar contenidos dinámicos.
4. ¿Es legal el Web Scraping?
El web scraping suele percibirse como algo controvertido o ilegal. Pero en realidad es una práctica legítima que, si se atiene a ciertos límites éticos y legales, es perfectamente legal.
La legalidad del web scraping depende de la naturaleza de los datos extraídos y de los métodos utilizados. El web scraping se considera lícito cuando se utiliza para recopilar información disponible públicamente en Internet. Sin embargo, siempre hay que tener cuidado, sobre todo cuando se trata de datos personales o contenidos protegidos por derechos de autor.
He aquí algunos consejos a tener en cuenta:
- No extraiga datos privados. También es ilegal extraer datos que no estén disponibles públicamente. Extraer datos detrás de una página de inicio de sesión, con usuario y contraseña de acceso, es ilegal en Estados Unidos, Canadá y la mayor parte de Europa.
- Lo que hagas con los datos es lo que puede meterte en problemas. El "web scraping" ético implica ser consciente de los datos que se recogen y de su finalidad. Debe prestarse especial atención a los datos personales y a la propiedad intelectual. Asegúrese de cumplir normativas como el GDPR y la CCPA, que regulan el tratamiento de los datos personales. Por ejemplo, la reutilización o reventa de contenidos o la descarga de material protegido por derechos de autor es ilegal (y debe evitarse).
- También es esencial revisar las condiciones de servicio de los sitios web. Se trata de documentos que indican a quienes utilizan sus servicios o contenidos cómo deben y no deben interactuar con los recursos.
- Garantice siempre alternativas como el uso de las API proporcionadas oficialmente. Algunos sitios web, como agencias gubernamentales, meteorológicas y plataformas de redes sociales (Facebook y Twitter) ponen algunos de sus datos a disposición del público a través de API.
- Considere la posibilidad de comprobar el archivo robots.txt. Este archivo se guarda en el servidor web y da instrucciones a los rastreadores y raspadores web sobre qué partes de un sitio web deben evitar y cuáles están autorizadas. También da instrucciones sobre los límites de velocidad.
- Evite iniciar ataques de web scraping. Dependiendo del contexto, a veces el web scraping se denomina ataque de scraping. Cuando los spammers utilizan botnets (ejércitos de bots) para atacar un sitio web con peticiones grandes y rápidas, el servicio de todo el sitio web puede fallar. Los raspados de datos a gran escala pueden provocar la caída de sitios web enteros.
Noticias recientes sobre los aspectos jurídicos del web scraping.
Recientes sentencias judiciales han aclarado que, en general, el raspado de datos de acceso público no se considera una infracción. Una sentencia histórica del Tribunal de Apelaciones de Estados Unidos reafirmó la legalidad del web scraping, al afirmar que el raspado de datos de acceso público en Internet no infringe la Ley de Fraude y Abuso Informático (CFAA) [fuente: TechCrunch].
en otras noticias, las recientes demandas contra OpenAI y Microsoft ponen de manifiesto la preocupación por la privacidad, la propiedad intelectual y las leyes contra el pirateo informático, según una noticia reciente de 2024 de julio [Bloomberg]. Aunque la CFAA tiene una eficacia limitada, se están estudiando las reclamaciones por incumplimiento de contrato y las leyes estatales sobre privacidad. La interacción entre los derechos de autor y el derecho contractual sigue sin resolverse, lo que deja muchas preguntas sin respuesta en el contexto del web scraping.
En las últimas noticias, [fuente: IndiaTimes] Elon Musk está cambiando las normas de Twitter para evitar niveles extremos de scraping de datos. Según Musk, el web scraping extremo afecta negativamente a la experiencia del usuario. Sugirió que las organizaciones que utilizan grandes modelos lingüísticos para la IA generativa eran las culpables.
5. ¿Cómo intentan los sitios web bloquear el web scraping?
Las empresas quieren que algunos de sus datos sean accesibles para los visitantes humanos. Pero cuando las empresas o los usuarios utilizan scripts automatizados o bots para extraer agresivamente datos del sitio, puede haber mucho abuso de la privacidad y de los recursos en un servidor web y una página objetivo. Estos sitios víctimas prefieren disuadir este tipo de tráfico.
Técnicas Anti-Scraping.
- Cantidades inusuales y elevadas de tráfico de una sola fuente. Los servidores web pueden utilizar WAF (Web Application Firewalls) con listas negras de direcciones IP ruidosas para bloquear el tráfico, filtros sobre tasas y tamaños de solicitudes "inusuales" y mecanismos de filtrado. Algunos sitios utilizan una combinación de WAF y CDN (redes de distribución de contenidos) para filtrar totalmente o reducir el ruido de esas IP.
- Algunos sitios web pueden detectar patrones de navegación similares a los de los robots. De forma similar a la técnica anterior, los sitios web también bloquean las solicitudes en función del User-Agent (encabezado HTTP). Los bots no utilizan un navegador normal. Estos bots tienen diferentes cadenas de agente de usuario (es decir, rastreador, araña o bot), falta de variación, ausencia de cabeceras (navegadores sin cabecera), tasas de solicitud, etc.
- Los sitios web también cambian a menudo el marcado HTML. Los robots de raspado web siguen una ruta coherente de "marcado HTML" cuando recorren el contenido de un sitio web. Algunos sitios web cambian los elementos HTML del marcado de forma regular y aleatoria. Esta técnica desvía a un bot de su hábito o programa de raspado habitual. Cambiar el marcado HTML no detiene el web scraping, pero lo hace mucho más difícil.
- El uso de retos como el CAPTCHA. Para evitar que los robots utilicen navegadores sin cabeza, algunos sitios web requieren retos CAPTCHA. Los robots que utilizan navegadores sin cabeza tienen dificultades para resolver este tipo de retos. Los CAPTCHA se crearon para ser resueltos por el usuario (a través del navegador) y no por robots.
- Algunos sitios son trampas (honeypots) para bots de raspado. Algunos sitios web se crean únicamente para atrapar bots de raspado, una técnica conocida como honeypots. Estos honeypots sólo son visibles para los bots de scraping (no para los visitantes humanos ordinarios) y se construyen para llevar a los scrapers web a una trampa.
6. Prácticas éticas y recomendadas para el Web Scraping.
El "web scraping" debe hacerse de forma responsable y ética. Como ya se ha mencionado, la lectura de los Términos y Condiciones o ToS debería darle una idea de las restricciones a las que debe atenerse. Si quieres hacerte una idea de las reglas de un rastreador web, consulta su ROBOTS.txt.
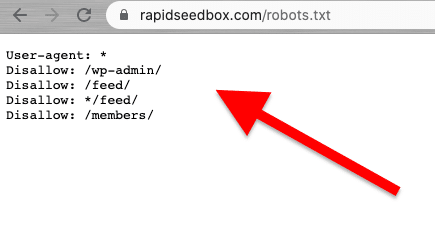
Si el web scraping está totalmente prohibido o bloqueado, utilice su API (si está disponible).
Además, hay que tener en cuenta el ancho de banda del sitio web de destino para evitar sobrecargar el servidor con demasiadas peticiones. Es crucial automatizar las peticiones con un ritmo y unos tiempos de espera adecuados para evitar sobrecargar el servidor de destino. La simulación de un usuario en tiempo real debería ser óptima. Además, nunca se deben raspar datos detrás de las páginas de inicio de sesión.
Sigue las normas y no te pasará nada.
Buenas prácticas de raspado web.
- Utilice un proxy. Un proxy es un servidor intermediario que reenvía peticiones. Cuando se hace web scraping con un proxy, se enruta la petición original a través de él. Así, el proxy mapea la petición con su propia IP y la reenvía al sitio web de destino. Utilice un proxy para:
- Elimine las posibilidades de que su IP sea incluida en una lista negra o bloqueada. Siempre hacer peticiones a través de varios proxies- proxies IPv6. son un buen ejemplo. Un grupo de proxy puede ayudarle a realizar solicitudes de mayor volumen sin que se bloqueen.
- Eludir los contenidos adaptados geográficamente. Un proxy en una región específica es útil para el scraping de datos según esa región geográfica concreta. Esto es útil cuando los sitios web y los servicios están detrás de una CDN.
- Rotación de apoderados. Los proxies rotatorios toman (rotan) una nueva IP del pool para cada nueva conexión. Tenga en cuenta que Las VPN no son proxies. Aunque hacen algo muy parecido, que es proporcionar anonimato, funcionan a niveles diferentes.
- Gire UA (agentes de usuario) y cabeceras de solicitud HTTP. Para rotar UAs y cabeceras HTTP, necesitarías recopilar una lista de cadenas UA de navegadores web reales. Pon la lista en tu código de web scraping en Python y configura las peticiones para que elijan cadenas aleatorias.
- No sobrepases los límites. Reduzca el número de solicitudes, rote y aleatorice. Si está realizando un gran número de solicitudes para un sitio web, empiece por aleatorizar las cosas. Haz que cada petición parezca aleatoria y humana. En primer lugar, cambie la IP de cada solicitud con la ayuda de proxies rotatorios. Además, utiliza diferentes cabeceras HTTP para que parezca que las peticiones proceden de otros navegadores.
7. Web Scraping FAQ: Preguntas más frecuentes.
a. ¿Qué es robots.txt y qué papel desempeña en el web scraping?
El robots.txt sirve como herramienta de comunicación entre propietarios de sitios web, rastreadores web y "scrapers". Se trata de un archivo de texto colocado en el servidor de un sitio web que proporciona instrucciones a los robots web (rastreadores, arañas web y otros robots automatizados) sobre las partes del sitio web a las que pueden acceder y raspar, y las que deben evitar. "Los robots de rastreo que se comportan bien (como Googlebot) están diseñados para leer automáticamente el archivo robots.txt. Los raspadores no están diseñados para leer este archivo. Por lo tanto, es muy importante conocer el archivo robots.txt para respetar los deseos del propietario del sitio web.
b. ¿Qué técnicas utilizan los administradores de sitios web para evitar intentos "abusivos" o "no autorizados" de web scraping?
No todos los scrapers extraen datos de forma ética y legal. No respetan las condiciones de servicio del sitio ni las directrices de robots.txt. Por ello, los administradores de sitios web pueden tomar medidas adicionales para proteger sus datos y recursos, como el bloqueo de IP o los desafíos CAPTCHA. También pueden utilizar medidas de limitación de velocidad, verificación del agente de usuario (para identificar posibles bots), seguimiento de sesiones, autenticación basada en tokens, redes de distribución de contenidos (CDN) o incluso sistemas de detección basados en el comportamiento.
c. Web Scraping vs. Web Crawling?
Aunque tanto el web scraping como el web crawling son técnicas de extracción de datos web, tienen diferentes propósitos, alcance, automatización y aspectos legales. Por un lado, las técnicas de web scraping tienen por objeto extraer datos específicos de sitios concretos. Son específicas y tienen un alcance limitado. El web scraping utiliza scripts automatizados o herramientas de terceros para solicitar, recibir, analizar, extraer y estructurar datos. Las técnicas de rastreo web, por su parte, se utilizan para buscar sistemáticamente en la web. Son populares entre los motores de búsqueda (ámbito más amplio), las plataformas de medios sociales, los investigadores, los agregadores de contenidos, etc. Los rastreadores web pueden visitar muchos sitios automáticamente (mediante bots, crawlers o spider), construir una lista, indexar datos (crear una copia) y almacenarlos en una base de datos. Los rastreadores web "suelen" comprobar los archivos ROBOTS.txt.
d. Data mining vs Data scraping: ¿Cuáles son sus diferencias y similitudes?
Tanto la minería de datos como el raspado de datos implican la extracción de datos. Sin embargo, la minería de datos se centra en el uso de técnicas estadísticas y de aprendizaje automático para analizar conjuntos de datos estructurados. Su objetivo es identificar patrones, relaciones y perspectivas en conjuntos de datos estructurados grandes y complejos. El scraping de datos, por su parte, se centra en "la parte de recopilación" de información específica de páginas y sitios web. Ambas técnicas y herramientas pueden utilizarse conjuntamente. El web scraping puede ser un paso preliminar para recopilar datos de la web, que luego se introducen en algoritmos de minería de datos para un análisis en profundidad y el descubrimiento de insights.
e. ¿Qué es el Screen Scraping? ¿Y qué relación tiene con el Data Scraping?
Ambas técnicas se centran en la extracción de datos, pero difieren en el tipo de datos que extraen. Raspado de pantalla tienen como objetivo capturar y extraer "automáticamente" los datos visuales que aparecen en sitios web y documentos, incluido el texto de la pantalla. A diferencia del web scraping, que analiza datos de HTML (extrayendo así una amplia gama de datos web), el screen scraping lee datos de texto directamente de la pantalla.
f. ¿Es lo mismo Web Harvesting que Web Scraping?
El raspado de datos y el web harvesting están estrechamente relacionados y a menudo se utilizan indistintamente, pero no son los mismos conceptos. El web harvesting tiene una connotación más amplia. Abarca diferentes métodos de extracción de datos de la web, incluidos varios mecanismos automáticos de extracción web, como el web scraping. Una distinción clara es que el web harvesting se utiliza a menudo cuando está implicada una API, en lugar de analizar directamente el código HTML de las páginas web (como hace el web scraping).
g. Selector CSS vs Selector xPath: ¿Cuáles son las diferencias en el scraping?
Los selectores CSS son una forma eficaz de extraer datos durante el scraping web. Ofrecen una sintaxis sencilla y funcionan bien en la mayoría de los escenarios de scraping. Sin embargo, en casos más complejos o cuando se trata de estructuras anidadas, los selectores Xpath pueden proporcionar flexibilidad y funcionalidad adicionales.
h. ¿Cómo manejar sitios web dinámicos con Selenium?
Selenium es una potente herramienta para el web scraping de sitios web dinámicos. Le permite interactuar con elementos de la página web como lo haría un usuario humano. Esta capacidad permite a su "script" navegar por contenidos generados dinámicamente. Mediante el uso de WebDriver de Seleniumpuede esperar a que se carguen los elementos de la página, interactuar con elementos AJAX y extraer datos de sitios web que dependen en gran medida de JavaScript.
i. ¿Cómo manejar AJAX y JavaScript durante el Web Scraping?
Cuando se trata de AJAX y JavaScript durante el web scraping, las librerías tradicionales como Requests y Beautiful Soup pueden no ser suficientes. Para gestionar las solicitudes AJAX y el contenido renderizado en JavaScript, puede utilizar herramientas como Selenium o navegadores headless como Titiritero.
¿Busca proxies fiables para el web scraping?
Aumente la eficacia de su raspado web con los servicios proxy de alta calidad de RapidSeedbox. Disfrute de un scraping rápido, seguro y anónimo.
8. Palabras Finales.
¡Enhorabuena! ¡Has completado la guía definitiva para el web scraping!
Esperamos que esta guía le haya proporcionado los conocimientos y herramientas necesarios para aprovechar el potencial del web scraping en sus proyectos.
Recuerda que un gran poder conlleva una gran responsabilidad. Al iniciar su viaje por el web scraping, dé siempre prioridad a las prácticas éticas, respete las condiciones de servicio de los sitios web y sea consciente de la privacidad de los datos.
Hemos tocado la punta del iceberg. Web Scraping puede ser un tema bastante amplio. Pero bueno, ¡ya has raspado un sitio web!
El aprendizaje continuo y el estar al día de las últimas tecnologías y novedades jurídicas le permitirán desenvolverse en este complejo mundo.
0Comentarios