Accessing and analyzing information online information is a crucial skill for businesses, researchers, and developers alike. One method we’ve covered before is web scraping, but there’s another technique called screen scraping.
This beginner’s guide is designed to explain the fundamentals of screen scraping and explore the tools and technologies, such as proxy servers, that make it possible.

Disclaimer: This material has been developed strictly for informational purposes. It does not constitute endorsement of any activities (including illegal activities), products or services. You are solely responsible for complying with the applicable laws, including intellectual property laws, when using our services or relying on any information herein. We do not accept any liability for damage arising from the use of our services or information contained herein in any manner whatsoever, except where explicitly required by law.
Table of Contents
- What is Screen Scraping?
- How Screen Scraping Works
- Screen Scraping vs. Web Scraping
- Common Uses of Screen Scraping
- Screen Scraping Tools and Technologies
- Programming Languages
- Screen Scraping Tools
- APIs vs. Screen Scraping
- Automation and Bots
- How to Get Started with Screen Scraping
- Setting Up Your Environment
- Choosing a Target Website
- Writing Your First Script
- Handling Data
- Dealing With Common Challenges
- Final Thoughts
1. What is Screen Scraping?
Screen scraping is a technique for extracting data from a website’s viewable portions. Unlike other forms of web scraping, which may interact with a website’s underlying data structures like APIs, screen scraping directly captures the information as it appears on the user’s screen.
a. How Screen Scraping Works
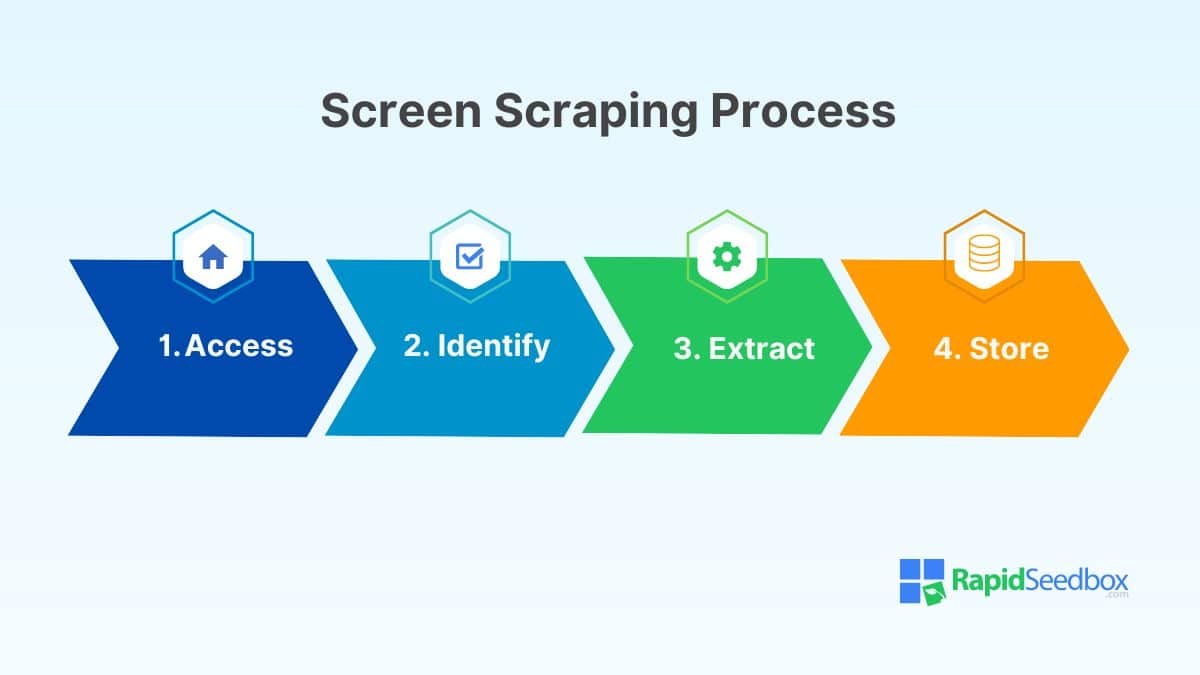
Screen scraping is like automating the process of copying data from a website. Because of that, the logical process is almost identical. Here’s a step-by-step breakdown:
- Accessing the Website: The scraper visits the website just as you would by typing the URL into your browser. The program can “see” everything on the page, including text, images, links, etc.
- Identifying the Data: Next, the program looks for specific information on the web page you want to collect. This could be anything from product names and prices to tables of data or lists of items.
- Extracting the Data: Once the program identifies the data, it “scrapes” or extracts it. This is similar to highlighting text on a webpage and copying it to your clipboard.
- Storing the Data: After extracting the information, the program stores it in a structured format, such as a CSV file, database, or spreadsheet.
b. Screen Scraping vs. Web Scraping
Screen scraping and web scraping are sometimes used interchangeably. However, they are not the same thing. While web scraping refers explicitly to extracting data from websites, screen scraping is a broader term that can apply to any program, not just web browsers.
Web scraping focuses on extracting data from web pages by directly parsing the HTML. In contrast, screen scraping might involve extracting data from non-HTML sources, such as desktop applications, PDFs, or even images displayed on the screen.
c. Common Uses of Screen Scraping
Screen scraping has a wide range of applications across various industries. Here are some of the most common uses:
- Data Extraction for Competitive Analysis: Businesses often use scraping to monitor competitors’ websites, gathering data on pricing, product availability, and promotional offers.
- Price Monitoring for E-commerce: Many platforms use screen scraping to track prices across competitor websites. This enables them to adjust their prices dynamically, ensuring they remain competitive and attract price-sensitive customers.
- Content Aggregation and Data Collection for Research: Screen scraping allows easy data collection from multiple sources, such as news websites, academic journals, or social media platforms.
- Job Listings and Real Estate Scraping: Screen scraping is commonly used to extract job listings or real estate data from multiple websites, allowing for centralized platforms (Think Zillow or RedFin).
2. Screen Scraping Tools and Technologies
While screen scraping is conceptually straightforward, it requires a solid understanding of the tools and technologies to execute effectively. Knowing the right tools can make the process much more manageable.
In this section, we’ll explore the essential programming languages, tools, and frameworks that can help you get started with screen scraping.
a. Programming Languages
Several programming languages can be used for screen scraping, but some are more popular due to their ease of use, robust libraries, and active communities. Here are the most commonly used languages for screen scraping:
- Python: The most favored programming language for screen scraping. It has a simple syntax and a vast array of libraries explicitly designed for this purpose. It’s also excellent for beginners due to its readability and extensive documentation.
- JavaScript: JavaScript, particularly with Node.js, is another popular option, especially for web applications. Libraries like Cheerio allow developers to interact with web pages and extract data dynamically.
- Ruby: With its library Nokogiri, Ruby is another popular language used for screen scraping. It offers a clean and expressive syntax, making it a good choice for those familiar with the language.
- Java: Particularly used in enterprise environments where Java-based applications are typical. Libraries like Jsoup allow for efficient HTML parsing and data extraction.
b. Screen Scraping Tools
Several tools and libraries can simplify the screen scraping process. Here’s an overview of some popular options:
- BeautifulSoup: A Python library that makes parsing HTML and XML documents easy. It allows you to navigate the parse tree and extract specific elements, making it ideal for scraping structured data from web pages.
- Scrapy: A robust Python framework designed for large-scale web scraping projects. It provides tools for managing requests, processing data, and handling complex scraping scenarios.
- Selenium: A versatile tool that automates web browsers, allowing you to scrape dynamic content that relies on JavaScript. Selenium is beneficial for scraping websites that require interaction.
- Pyppeteer: An unofficial Node.js library that provides a high-level API to control headless Chrome or Chromium browsers. Pyppeteer is excellent for scraping content rendered by JavaScript, taking screenshots, and automating browser tasks.
- Jsoup: A Java library for working with real-world HTML. It provides a convenient API for extracting and manipulating data from URLs and HTML files.
c. APIs vs. Screen Scraping
While screen scraping can be powerful, other methods may sometimes be more suitable. On many occasions, using an API is more efficient and ethical.
An API is a set of protocols that allows one application to communicate with another. Many websites offer APIs that provide structured access to their data, making it easier to retrieve information without needing to scrape it from the HTML.
However, there are situations where screen scraping might be necessary:
- No API Available: Some websites do not offer an API, making screen scraping the only option to access their data.
- Limited API Access: Some APIs have limitations, such as rate limits or restricted access to certain data types. Screen scraping can bypass these limitations, albeit with certain risks and ethical considerations.
- Custom Data Needs: Sometimes, an API does not provide the specific data you need or format it in a way that’s useful for your purposes. Screen scraping allows you to extract and structure the data precisely as needed.
d. Automation and Bots
Automation is a crucial aspect of screen scraping, especially when dealing with large datasets or tasks that must be repeated regularly. Bots are scripts or programs that automate accessing webpages, extracting and storing data.
These bots can be simple scripts that run periodically or complex systems that handle thousands of requests simultaneously.
Some fundamental automation techniques include:
- Scheduling Scraping Tasks: Using cron jobs (Linux) or Task Scheduler (Windows) to run your scraping scripts regularly.
- Using Proxies: Bots often use proxy servers to distribute requests across multiple IP addresses and avoid being blocked by websites.
- Handling CAPTCHAs: Many websites use CAPTCHAs to prevent automated access. Advanced bots bypass these challenges using services or techniques like image recognition or CAPTCHA-solving services.
Worried about getting blocked while scraping?
RapidSeedbox provides a vast network of rotating proxies that ensure your IP address stays fresh, reducing the risk of being blocked. Enjoy seamless access to websites and scrape with confidence using our trusted proxies.
3. How to Get Started with Screen Scraping
Starting with screen scraping can initially seem daunting, but by following a structured approach, beginners can quickly learn to extract data from websites effectively.
This section provides a step-by-step guide to help you set up your environment, choose a target website, write your first script, handle data, and tackle common challenges you might encounter along the way.
a. Setting Up Your Environment
Before you can begin scraping, you’ll need to set up your development environment. This involves installing the necessary tools and libraries that will enable you to write and run your scraping scripts.
- Install Python: If you haven’t already, download and install Python from the official website.
- Set Up a Virtual Environment: It’s good practice to create a virtual environment for your project. This isolates your project dependencies and prevents conflicts with other Python projects on your machine.
You can create a virtual environment by running:
|
1 2 |
python -m venv scraping-env source scraping-env/bin/activate # On Windows, use `scraping-env\Scripts\activate` |
- Install Required Libraries: For most screen scraping tasks, you’ll need libraries like BeautifulSoup for parsing HTML and requests for making HTTP requests. You can install them using pip:
|
1 |
pip install beautifulsoup4 requests |
- Install a Code Editor: While any text editor will do, using a code editor like VS Code, PyCharm, or Sublime Text can make writing and debugging your scripts easier.
b. Choosing a Target Website
While most websites are on the table for screen scraping, not all are ideal for beginners. When choosing a target website, consider the following factors:
- Website Structure: Start with websites that have a simple, well-structured HTML. Blogs, news sites, and e-commerce websites often have well-organized layouts, making identifying the elements you want to scrape easier.
- Ethical Considerations: Always ensure that scraping is allowed by checking the website’s robots.txt file and terms of service. Some websites explicitly prohibit scraping, and ignoring these rules can lead to legal issues.
- Static vs. Dynamic Content: Begin with websites that use static content (HTML that doesn’t change after the page loads). Dynamic websites, which load content via JavaScript after the initial page load, are more complex and require tools like Selenium or Puppeteer.
- Test on a Small Scale: Choose a website with a manageable amount of data. This allows you to practice and refine your scraping skills without overwhelming your script or system.
c. Writing Your First Script
With your environment set up and a target website chosen, you’re ready to write your first scraping script. Below is a basic example of scraping data from a simple webpage.
This simple script fetches a webpage, parses it for specific data (headings in this case), and saves that data to a CSV file.
Step 1: Import Libraries
Start by importing the necessary libraries:
|
1 2 |
import requests from bs4 import BeautifulSoup |
Step 2: Send an HTTP Request
Use the requests library to send a GET request to the webpage you want to scrape:
|
1 2 3 4 5 6 7 8 |
url = "https://example.com" response = requests.get(url) # Check if the request was successful if response.status_code == 200: print("Successfully fetched the webpage") else: print("Failed to retrieve the webpage") |
Step 3: Parse the HTML
Use BeautifulSoup to parse the HTML content:
|
1 |
soup = BeautifulSoup(response.text, 'html.parser') |
Step 4: Extract Data
Identify the HTML elements containing the data you want. For example, to extract all the headings on a page:
|
1 2 3 |
headings = soup.find_all('h1') # Finds all h1 tags for heading in headings: print(heading.text.strip()) # Prints the text inside the h1 tags |
Step 5: Store Data (Python)
Once you’ve extracted the data, you can store it in a file or database. For example, saving to a CSV file:
|
1 2 3 4 5 6 7 |
import csv with open('headings.csv', 'w', newline='') as file: writer = csv.writer(file) writer.writerow(["Heading"]) for heading in headings: writer.writerow([heading.text.strip()]) |
d. Handling Data
After scraping data, the next step is often to process and store it in a way that’s useful for your needs. Here are some standard methods for handling scraped data:
- Data Cleaning: Scraped data might need cleaning, such as removing HTML tags, trimming whitespace, or handling missing values. Python’s built-in string methods or libraries like Pandas can help with this.
- Storing Data: Depending on the size and structure of the data, you might choose to store it in different formats:
- CSV/Excel Files are ideal for small to medium datasets
- JSON is useful for hierarchical data or when you need to preserve the structure of nested elements.
- Keeping data in a database like SQLite or PostgreSQL is more efficient for larger datasets or when you need to query it.
- Data Analysis: Once stored, you can analyze the data using tools like Pandas for statistical analysis, Matplotlib for visualization, or even machine learning libraries like Scikit-learn if your project involves predictive analytics.
e. Dealing With Common Challenges
Screen scraping has its challenges. As you work on more advanced projects, you may encounter some of the following issues:
- Anti-Scraping Mechanisms: Websites often use techniques to prevent scraping, such as blocking IP addresses after multiple requests. Tools like Selenium or Pyppeteer can help overcome some of these challenges.
- Handling Dynamic Content: Many modern websites load content dynamically using JavaScript. Tools like Selenium allow you to load and scrape these dynamic elements.
- CAPTCHAs and Login Forms: If the website requires user interaction, your script must handle these steps. You can use third-party services or machine-learning techniques to solve CAPTCHAs.
- Rate Limiting: To avoid being blocked, you should implement rate limiting in your scraping scripts. This involves adding delays between requests or using proxies to spread the load across IP addresses.
4. Final Thoughts
You can start your screen scraping projects now that you have a solid foundation. With practice, you’ll be able to tackle increasingly complex challenges, extract deeper insights, and unlock the full potential of the web’s vast resources.
Whether you’re using screen scraping for research, business intelligence, or personal projects, the skills you’ve developed will open up new possibilities for data analysis and automation.
Just remember that there may be legal challenges to consider while screen scraping.
Is scraping slow due to rate limits?
RapidSeedbox proxies allow you to distribute your requests across multiple IPs, helping you avoid rate limits and get the data you need faster. Boost your scraping efficiency and stay under the radar with our top-tier proxies.
0Comments